| DNA barcoding |
|---|
 |
| By taxa |
| Other |
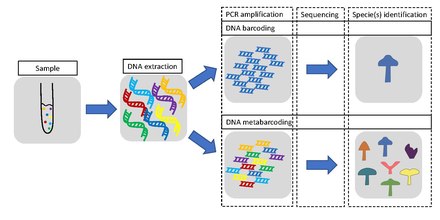
Metabarcoding is the barcoding of DNA/RNA (or eDNA/eRNA) in a manner that allows for the simultaneous identification of many taxa within the same sample. The main difference between barcoding and metabarcoding is that metabarcoding does not focus on one specific organism, but instead aims to determine species composition within a sample.
A barcode consists of a short variable gene region (for example, see different markers/barcodes) which is useful for taxonomic assignment flanked by highly conserved gene regions which can be used for primer design. This idea of general barcoding originated in 2003 from researchers at the University of Guelph.
The metabarcoding procedure, like general barcoding, proceeds in order through stages of DNA extraction, PCR amplification, sequencing and data analysis. Different genes are used depending if the aim is to barcode single species or metabarcoding several species. In the latter case, a more universal gene is used. Metabarcoding does not use single species DNA/RNA as a starting point, but DNA/RNA from several different organisms derived from one environmental or bulk sample.
Environmental DNA
Environmental DNA or eDNA describes the genetic material present in environmental samples such as sediment, water, and air, including whole cells, extracellular DNA and potentially whole organisms. eDNA can be captured from environmental samples and preserved, extracted, amplified, sequenced, and categorized based on its sequence. From this information, detection and classification of species is possible. eDNA may come from skin, mucous, saliva, sperm, secretions, eggs, feces, urine, blood, roots, leaves, fruit, pollen, and rotting bodies of larger organisms, while microorganisms may be obtained in their entirety. eDNA production is dependent on biomass, age and feeding activity of the organism as well as physiology, life history, and space use.
By 2019 methods in eDNA research had been expanded to be able to assess whole communities from a single sample. This process involves metabarcoding, which can be precisely defined as the use of general or universal polymerase chain reaction (PCR) primers on mixed DNA samples from any origin followed by high-throughput next-generation sequencing (NGS) to determine the species composition of the sample. This method has been common in microbiology for years, but, as of 2020, it is only just finding its footing in the assessment of macroorganisms. Ecosystem-wide applications of eDNA metabarcoding have the potential to not only describe communities and biodiversity, but also to detect interactions and functional ecology over large spatial scales, though it may be limited by false readings due to contamination or other errors. Altogether, eDNA metabarcoding increases speed, accuracy, and identification over traditional barcoding and decreases cost, but needs to be standardized and unified, integrating taxonomy and molecular methods for full ecological study.


with environmental DNA metabarcoding
eDNA metabarcoding has applications to diversity monitoring across all habitats and taxonomic groups, ancient ecosystem reconstruction, plant-pollinator interactions, diet analysis, invasive species detection, pollution responses, and air quality monitoring. eDNA metabarcoding is a unique method still in development and will likely remain in flux for some time as technology advances and procedures become standardized. However, as metabarcoding is optimized and its use becomes more widespread, it is likely to become an essential tool for ecological monitoring and global conservation study.
Community DNA
Since the inception of high‐throughput sequencing (HTS), the use of metabarcoding as a biodiversity detection tool has drawn immense interest. However, there has yet to be clarity regarding what source material is used to conduct metabarcoding analyses (e.g., environmental DNA versus community DNA). Without clarity between these two source materials, differences in sampling, as well as differences in laboratory procedures, can impact subsequent bioinformatics pipelines used for data processing, and complicate the interpretation of spatial and temporal biodiversity patterns. Here, we seek to clearly differentiate among the prevailing source materials used and their effect on downstream analysis and interpretation for environmental DNA metabarcoding of animals and plants compared to that of community DNA metabarcoding.
With community DNA metabarcoding of animals and plants, the targeted groups are most often collected in bulk (e.g., soil, malaise trap or net), and individuals are removed from other sample debris and pooled together prior to bulk DNA extraction. In contrast, macro‐organism eDNA is isolated directly from an environmental material (e.g., soil or water) without prior segregation of individual organisms or plant material from the sample and implicitly assumes that the whole organism is not present in the sample. Of course, community DNA samples may contain DNA from parts of tissues, cells and organelles of other organisms (e.g., gut contents, cutaneous intracellular or extracellular DNA). Likewise, macro‐organism eDNA samples may inadvertently capture whole microscopic nontarget organisms (e.g., protists, bacteria). Thus, the distinction can at least partly break down in practice.
Another important distinction between community DNA and macro‐organism eDNA is that sequences generated from community DNA metabarcoding can be taxonomically verified when the specimens are not destroyed in the extraction process. Here, sequences can then be generated from voucher specimens using Sanger sequencing. As the samples for eDNA metabarcoding lack whole organisms, no such in situ comparisons can be made. Taxonomic affinities can therefore only be established by directly comparing obtained sequences (or through bioinformatically generated operational taxonomic units (MOTUs)), to sequences that are taxonomically annotated such as NCBI's GenBank nucleotide database, BOLD, or to self‐generated reference databases from Sanger‐sequenced DNA. (The molecular operational taxonomic unit (MOTU) is a group identified through use of cluster algorithms and a predefined percentage sequence similarity, for example, 97%)). Then, to at least partially corroborate the resulting list of taxa, comparisons are made with conventional physical, acoustic or visual‐based survey methods conducted at the same time or compared with historical records from surveys for a location (see Table 1).
The difference in source material between community DNA and eDNA therefore has distinct ramifications for interpreting the scale of inference for time and space about the biodiversity detected. From community DNA, it is clear that the individual species were found in that time and place, but for eDNA, the organism that produced the DNA may be upstream from the sampled location, or the DNA may have been transported in the faeces of a more mobile predatory species (e.g., birds depositing fish eDNA, or was previously present, but no longer active in the community and detection is from DNA that was shed years to decades before. The latter means that the scale of inference both in space and in time must be considered carefully when inferring the presence for the species in the community based on eDNA.
Metabarcoding stages

There are six stages or steps in DNA barcoding and metabarcoding. The DNA barcoding of animals (and specifically of bats) is used as an example in the diagram at the right and in the discussion immediately below.
First, suitable DNA barcoding regions are chosen to answer some specific research question. The most commonly used DNA barcode region for animals is a segment about 600 base pairs long of the mitochondrial gene cytochrome oxidase I (CO1). This locus provides large sequence variation between species yet relatively small amount of variation within species. Other commonly used barcode regions used for species identification of animals are ribosomal DNA (rDNA) regions such as 16S, 18S and 12S and mitochondrial regions such as cytochrome B. These markers have advantages and disadvantages and are used for different purposes. Longer barcode regions (at least 600 base pairs long) are often needed for accurate species delimitation, especially to differentiate close relatives. Identification of the producer of organism's remains such as faeces, hairs and saliva can be used as a proxy measure to verify absence/presence of a species in an ecosystem. The DNA in these remains is usually of low quality and quantity, and therefore, shorter barcodes of around 100 base pairs long are used in these cases. Similarly, DNA remains in dung are often degraded as well, so short barcodes are needed to identify prey consumed.
Second, a reference database needs to be built of all DNA barcodes likely to occur in a study. Ideally, these barcodes need to be generated from vouchered specimens deposited in a publicly accessible place, such as for instance a natural history museum or another research institute. Building up such reference databases is currently being done all over the world. Partner organizations collaborate in international projects such as the International Barcode of Life Project (iBOL) and Consortium for the Barcode of Life (CBOL), aiming to construct a DNA barcode reference that will be the foundation for DNA‐based identification of the world's biome. Well‐known barcode repositories are NCBI GenBank and the Barcode of Life Data System (BOLD).
Third, the cells containing the DNA of interest must be broken open to expose its DNA. This step, DNA extractions and purifications, should be performed from the substrate under investigation. There are several procedures available for this. Specific techniques must be chosen to isolate DNA from substrates with partly degraded DNA, for example fossil samples, and samples containing inhibitors, such as blood, faeces and soil. Extractions in which DNA yield or quality is expected to be low should be carried out in an ancient DNA facility, together with established protocols to avoid contamination with modern DNA. Experiments should always be performed in duplicate and with positive controls included.
Fourth, amplicons have to be generated from DNA extracted, either from a single specimen or from complex mixtures with primers based on DNA barcodes selected under step 1. To keep track of their origin, labelled nucleotides (molecular IDs or MID labels) need to be added in case of metabarcoding. These labels are needed later on in the analyses to trace reads from a bulk data set back to their origin.

Fifth, the appropriate techniques should be chosen for DNA sequencing. The classic Sanger chain‐termination method relies on the selective incorporation of chain‐elongating inhibitors of DNA polymerase during DNA replication. These four bases are separated by size using electrophoresis and later identified by laser detection. The Sanger method is limited and can produce a single read at the same time and is therefore suitable to generate DNA barcodes from substrates that contain only a single species. Emerging technologies such as nanopore sequencing have resulted in the cost of DNA sequencing reducing from about USD 30,000 per megabyte in 2002 to about USD 0.60 in 2016. Modern next-generation sequencing (NGS) technologies can handle thousands to millions reads in parallel and are therefore suitable for mass identification of a mix of different species present in a substrate, summarized as metabarcoding.
Finally, bioinformatic analyses need to be carried out to match DNA barcodes obtained with Barcode Index Numbers (BINs) in reference libraries. Each BIN, or BIN cluster, can be identified to species level when it shows high (>97%) concordance with DNA barcodes linked to a species present in a reference library, or when taxonomic identification to the species level is still lacking, an operational taxonomic unit (OTU), which refers to a group of species (i.e. genus, family or higher taxonomic rank). (See binning (metagenomics)). The results of the bioinformatics pipeline must be pruned, for example by filtering out unreliable singletons, superfluous duplicates, low‐quality reads and/or chimeric reads. This is generally done by carrying out serial BLAST searches in combination with automatic filtering and trimming scripts. Standardized thresholds are needed to discriminate between different species or a correct and a wrong identification.
Metabarcoding workflow
Despite the obvious power of the approach, eDNA metabarcoding is affected by precision and accuracy challenges distributed throughout the workflow in the field, in the laboratory and at the keyboard. As set out in the diagram at the right, following the initial study design (hypothesis/question, targeted taxonomic group etc) the current eDNA workflow consists of three components: field, laboratory and bioinformatics. The field component consists of sample collection (e.g., water, sediment, air) that is preserved or frozen prior to DNA extraction. The laboratory component has four basic steps: (i) DNA is concentrated (if not performed in the field) and purified, (ii) PCR is used to amplify a target gene or region, (iii) unique nucleotide sequences called “indexes” (also referred to as “barcodes”) are incorporated using PCR or are ligated (bound) onto different PCR products, creating a “library” whereby multiple samples can be pooled together, and (iv) pooled libraries are then sequenced on a high‐throughput machine. The final step after laboratory processing of samples is to computationally process the output files from the sequencer using a robust bioinformatics pipeline.

of an environmental DNA metabarcoding study

Method and visualisation

b) Beta diversity patterns illustrated via Principal Coordinate Analyses carried out in QIIME, where each dot represents a sample and colors distinguish different classes of sample. The closer two sample points in 3D space, the more similar their community assemblages
c) GraPhalAn phylogenetic visualization of environmental data, with circular heatmaps and abundance bars used to convey quantitative taxon traits.
d) Edge PCA, a tree‐based diversity metric that identifies specific lineages (green/orange branches) that contribute most to community changes observed in samples distributed across different PCA axes.
The method requires each collected DNA to be archived with its corresponding "type specimen" (one for each taxon), in addition to the usual collection data. These types are stored in specific institutions (museums, molecular laboratories, universities, zoological gardens, botanical gardens, herbaria, etc.) one for each country, and in some cases, the same institution is assigned to contain the types of more than a country, in cases where some nations do not have the technology or financial resources to do so.
In this way, the creation of type specimens of genetic codes represents a methodology parallel to that carried out by traditional taxonomy.
In a first stage, the region of the DNA that would be used to make the barcode was defined. It had to be short and achieve a high percentage of unique sequences. For animals, algae and fungi, a portion of a mitochondrial gene which codes for subunit 1 of the cytochrome oxidase enzyme, CO1, has provided high percentages (95%), a region around 648 base pairs.
In the case of plants, the use of CO1 has not been effective since they have low levels of variability in that region, in addition to the difficulties that are produced by the frequent effects of polyploidy, introgression, and hybridization, so the chloroplast genome seems more suitable.
Applications
Pollinator networks

(a,b) plant-pollinator groups
(c,d) plant-pollinator species
(e,f) individual pollinator-plant species
(Empis leptempis pandellei)
Line thickness highlights the proportion of interactions
The diagram on the right shows a comparison of pollination networks based on DNA metabarcoding with more traditional networks based on direct observations of insect visits to plants. By detecting numerous additional hidden interactions, metabarcoding data largely alters the properties of the pollination networks compared to visit surveys. Molecular data shows that pollinators are much more generalist than expected from visit surveys. However, pollinator species were composed of relatively specialized individuals and formed functional groups highly specialized upon floral morphs.
As a consequence of the ongoing global changes, a dramatic and parallel worldwide decline in pollinators and animal-pollinated plant species has been observed. Understanding the responses of pollination networks to these declines is urgently required to diagnose the risks the ecosystems may incur as well as to design and evaluate the effectiveness of conservation actions. Early studies on animal pollination dealt with simplified systems, i.e. specific pairwise interactions or involved small subsets of plant-animal communities. However, the impacts of disturbances occur through highly complex interaction networks and, nowadays, these complex systems are currently a major research focus. Assessing the true networks (determined by ecological process) from field surveys that are subject to sampling effects still provides challenges.
Recent research studies have clearly benefited from network concepts and tools to study the interaction patterns in large species assemblages. They showed that plant-pollinator networks were highly structured, deviating significantly from random associations. Commonly, networks have (1) a low connectance (the realized fraction of all potential links in the community) suggesting a low degree of generalization; (2) a high nestedness (the more-specialist organisms are more likely to interact with subsets of the species that more-generalist organisms interact with) the more specialist species interact only with proper subsets of those species interacting with the more generalist ones; (3) a cumulative distribution of connectivity (number of links per species, s) that follows a power or a truncated power law function characterized by few supergeneralists with more links than expected by chance and many specialists; (4) a modular organization. A module is a group of plant and pollinator species that exhibits high levels of within-module connectivity, and that is poorly connected to species of other groups.
The low level of connectivity and the high proportion of specialists in pollination networks contrast with the view that generalization rather than specialization is the norm in networks. Indeed, most plants species are visited by a diverse array of pollinators which exploit floral resources from a wide range of plant species. A main cause evoked to explain this apparent contradiction is the incomplete sampling of interactions. Indeed, most network properties are highly sensitive to sampling intensity and network size. Network studies are basically phytocentric i.e. based on the observations of pollinator visits to flowers. This plant-centered approach suffers nevertheless from inherent limitations which may hamper the comprehension of mechanisms contributing to community assembly and biodiversity patterns. First, direct observations of pollinator visits to certain taxa such as orchids are often scarce and rare interactions are very difficult to detect in field in general. Pollinator and plant communities usually are composed of few abundant species and many rare species that are poorly recorded in visit surveys. These rare species appear as specialists, whereas in fact they could be typical generalists. Because of the positive relationship between interaction frequency (f) and connectivity (s), undersampled interactions may lead to overestimating the degree of specialization in networks. Second, network analyses have mostly operated at species levels. Networks have very rarely been up scaled to the functional groups or down scaled to the individual-based networks, and most of them have been focused on one or two species only. The behavior of either individuals or colonies is commonly ignored, although it may influence the structure of the species networks. Species accounted as generalists in species networks could, therefore, entail cryptic specialized individuals or colonies. Third, flower visitors are by no means always effective pollinators as they may deposit no conspecific pollen and/or a lot of heterospecific pollen. Animal-centered approaches based on the investigation of pollen loads on visitors and plant stigmas may be more efficient at revealing plant-pollinator interactions.
Disentangling food webs

(A) Trophic network:
of arthropod and vertebrate predators – arrows represent biomass flow between predators and preys.
(B) Intraguild interactions: * Arthropod predators * Parasitoids of arthropods: * Insectivorous vertebrates:
Metabarcoding offers new opportunities for deciphering trophic linkages between predators and their prey within food webs. Compared to traditional, time-consuming methods, such as microscopic or serological analyses, the development of DNA metabarcoding allows the identification of prey species without prior knowledge of the predator’s prey range. In addition, metabarcoding can also be used to characterize a large number of species in a single PCR reaction, and to analyze several hundred samples simultaneously. Such an approach is increasingly used to explore the functional diversity and structure of food webs in agroecosystems. Like other molecular-based approaches, metabarcoding only gives qualitative results on the presence/absence of prey species in the gut or fecal samples. However, this knowledge of the identity of prey consumed by predators of the same species in a given environment enables a "pragmatic and useful surrogate for truly quantitative information.
In food web ecology, "who eats whom" is a fundamental issue for gaining a better understanding of the complex trophic interactions existing between pests and their natural enemies within a given ecosystem. The dietary analysis of arthropod and vertebrate predators allows the identification of key predators involved in the natural control of arthropod pests and gives insights into the breadth of their diet (generalist vs. specialist) and intraguild predation.
The diagram on the right summarises results from a 2020 study which used metabarcoding to untangle the functional diversity and structure of the food web associated with a couple of millet fields in Senegal. After assigning the identified OTUs as species, 27 arthropod prey taxa were identified from nine arthropod predators. The mean number of prey taxa detected per sample was the highest in carabid beetles , ants and spiders, and the lowest in the remaining predators including anthocorid bugs, pentatomid bugs, and earwigs. Across predatory arthropods, a high diversity of arthropod preys was observed in spiders, carabid beetles, ants, and anthocorid bugs. In contrast, the diversity of prey species identified in earwigs and pentatomid bugs was relatively low. Lepidoptera, Hemiptera, Diptera and Coleoptera were the most common insect prey taxa detected from predatory arthropods.
Conserving functional biodiversity and related ecosystem services, especially by controlling pests using their natural enemies, offers new avenues to tackle challenges for the sustainable intensification of food production systems. Predation of crop pests by generalist predators, including arthropods and vertebrates, is a major component of natural pest control. A particularly important trait of most generalist predators is that they can colonize crops early in the season by first feeding on alternative prey. However, the breadth of the "generalist" diet entails some drawbacks for pest control, such as intra-guild predation. A tuned diagnosis of diet breadth in generalist predators, including predation of non-pest prey, is thus needed to better disentangle food webs (e.g., exploitation competition and apparent competition) and ultimately to identify key drivers of natural pest control in agroecosystems. However, the importance of generalist predators in the food web is generally difficult to assess, due to the ephemeral nature of individual predator–prey interactions. The only conclusive evidence of predation results from direct observation of prey consumption, identification of prey residues within predators’ guts, and analyses of regurgitates or feces.
Marine biosecurity

.jpeg)


The spread of non-indigenous species (NIS) represents significant and increasing risks to ecosystems. In marine systems, NIS that survive the transport and adapt to new locations can have significant adverse effects on local biodiversity, including the displacement of native species, and shifts in biological communities and associated food webs. Once NIS are established, they are extremely difficult and costly to eradicate, and further regional spread may occur through natural dispersal or via anthropogenic transport pathways. While vessel hull fouling and ships’ ballast waters are well known as important anthropogenic pathways for the international spread of NIS, comparatively little is known about the potential of regionally transiting vessels to contribute to the secondary spread of marine pests through bilge water translocation.
Recent studies have revealed that the water and associated debris entrained in bilge spaces of small vessels (<20 m) can act as a vector for the spread of NIS at regional scales. Bilge water is defined as any water that is retained on a vessel (other than ballast), and that is not deliberately pumped on board. It can accumulate on or below the vessel’s deck (e.g., under floor panels) through a variety of mechanisms, including wave actions, leaks, via the propeller stern glands, and through the loading of items such as diving, fishing, aquaculture or scientific equipment. Bilge water, therefore, may contain seawater as well as living organisms at various life stages, cell debris and contaminants (e.g., oil, dirt, detergent, etc.), all of which are usually discharged using automatic bilge pumps or are self-drained using duckbill valves. Bilge water pumped from small vessels (manually or automatically) is not usually treated prior to discharge to sea, contrasting with larger vessels that are required to separate oil and water using filtration systems, centrifugation, or carbon absorption. If propagules are viable through this process, the discharge of bilge water may result in the spread of NIS.
In 2017, Fletcher et al. used a combination of laboratory and field experiments to investigate the diversity, abundance, and survival of biological material contained in bilge water samples taken from small coastal vessels. Their laboratory experiment showed that ascidian colonies or fragments, and bryozoan larvae, can survive passage through an unfiltered pumping system largely unharmed. They also conducted the first morpho-molecular assessment (using eDNA metabarcoding) on the biosecurity risk posed by bilge water discharges from 30 small vessels (sailboats and motorboats) of various origins and sailing time. Using eDNA metabarcoding they characterised approximately three times more taxa than via traditional microscopic methods, including the detection of five species recognised as non-indigenous in the study region.
To assist in understanding the risks associated with different NIS introduction vectors, traditional microscope biodiversity assessments are increasingly being complemented by eDNA metabarcoding. This allows a wide range of diverse taxonomic assemblages, at many life stages to be identified. It can also enable the detection of NIS that may have been overlooked using traditional methods. Despite the great potential of eDNA metabarcoding tools for broad-scale taxonomic screening, a key challenge for eDNA in the context of environmental monitoring of marine pests, and particularly when monitoring enclosed environments such as some bilge spaces or ballast tanks, is differentiating dead and viable organisms. Extracellular DNA can persist in dark/cold environments for extended periods of time (months to years, thus many of the organisms detected using eDNA metabarcoding may have not been viable in the location of sample collection for days or weeks. In contrast, ribonucleic acid (RNA) deteriorates rapidly after cell death, likely providing a more accurate representation of viable communities. Recent metabarcoding studies have explored the use of co-extracted eDNA and eRNA molecules for monitoring benthic sediment samples around marine fish farms and oil drilling sites, and have collectively found slightly stronger correlations between biological and physico-chemical variables along impact gradients when using eRNA. From a marine biosecurity prospective, the detection of living NIS may represent a more serious and immediate threat than the detection of NIS based purely on a DNA signal. Environmental RNA may therefore offer a useful method for identifying living organisms in samples.
Miscellaneous
The construction of the genetic barcode library was initially focused on fish and the birds, which were followed by butterflies and other invertebrates. In the case of birds, the DNA sample is usually obtained from the chest.
Researchers have already developed specific catalogs for large animal groups, such as bees, birds, mammals or fish. Another use is to analyze the complete zoocenosis of a given geographic area, such as the "Polar Life Bar Code" project that aims to collect the genetic traits of all organisms that live in polar regions; both poles of the Earth. Related to this form is the coding of all the ichthyofauna of a hydrographic basin, for example the one that began to develop in the Rio São Francisco, in the northeast of Brazil.
The potential of the use of Barcodes is very wide, since the discovery of numerous cryptic species (it has already yielded numerous positive results), the use in the identification of species at any stage of their life, the secure identification in cases of protected species that are illegally trafficked, etc.
Potentials and shortcomings

Potentials
DNA barcoding has been proposed as a way to distinguish species suitable even for non-specialists to use.
Shortcomings
In general, the shortcomings for DNA barcoding are valid also for metabarcoding. One particular drawback for metabarcoding studies is that there is no consensus yet regarding the optimal experimental design and bioinformatics criteria to be applied in eDNA metabarcoding. However, there are current joined attempts, like e.g. the EU COST network DNAqua-Net, to move forward by exchanging experience and knowledge to establish best-practice standards for biomonitoring.
The so-called barcode is a region of mitochondrial DNA within the gene for cytochrome c oxidase. A database, Barcode of Life Data Systems (BOLD), contains DNA barcode sequences from over 190,000 species. However, scientists such as Rob DeSalle have expressed concern that classical taxonomy and DNA barcoding, which they consider a misnomer, need to be reconciled, as they delimit species differently. Genetic introgression mediated by endosymbionts and other vectors can further make barcodes ineffective in the identification of species.
Status of barcode species
In microbiology, genes can move freely even between distantly related bacteria, possibly extending to the whole bacterial domain. As a rule of thumb, microbiologists have assumed that kinds of Bacteria or Archaea with 16S ribosomal RNA gene sequences more similar than 97% to each other need to be checked by DNA-DNA hybridisation to decide if they belong to the same species or not. This concept was narrowed in 2006 to a similarity of 98.7%.
DNA-DNA hybridisation is outdated, and results have sometimes led to misleading conclusions about species, as with the pomarine and great skua. Modern approaches compare sequence similarity using computational methods.


.jpg)






