An f-test pdf with d1 and d2 = 10, at a significance level of 0.05. (Red shaded region indicates the critical region)
An F-test is a statistical test
that compares variances. It's used to determine if the variances of two
samples, or if the ratios of variances among multiple samples, are
significantly different. The test calculates a statistic, represented by the random variable F, and checks if it follows an F-distribution. This check is valid if the null hypothesis is true and standard assumptions about the errors (ε) in the data hold.
F-tests are frequently used to compare different statistical models and find the one that best describes the population the data came from. When models are created using the least squares method, the resulting F-tests are often called "exact" F-tests. The F-statistic was developed by Ronald Fisher in the 1920s as the variance ratio and was later named in his honor by George W. Snedecor.
Common examples
Common examples of the use of F-tests include the study of the following cases
One-way ANOVA table with 3 random groups that each has 30 observations. F value is being calculated in the second to last columnThe hypothesis that the means of a given set of normally distributed populations, all having the same standard deviation, are equal. This is perhaps the best-known F-test, and plays an important role in the analysis of variance (ANOVA).
The hypothesis that a data set in a regression analysis follows the simpler of two proposed linear models that are nested within each other.
Multiple-comparison testing is conducted using needed data in
already completed F-test, if F-test leads to rejection of null
hypothesis and the factor under study has an impact on the dependent
variable.
"a priori comparisons"/ "planned comparisons"- a particular set of comparisons
Most F-tests arise by considering a decomposition of the variability in a collection of data in terms of sums of squares. The test statistic in an F-test
is the ratio of two scaled sums of squares reflecting different sources
of variability. These sums of squares are constructed so that the
statistic tends to be greater when the null hypothesis is not true. In
order for the statistic to follow the F-distribution under the null hypothesis, the sums of squares should be statistically independent, and each should follow a scaled χ²-distribution. The latter condition is guaranteed if the data values are independent and normally distributed with a common variance.
One-way analysis of variance
The formula for the one-way ANOVAF-test statistic is
or
The "explained variance", or "between-group variability" is
where denotes the sample mean in the i-th group, is the number of observations in the i-th group, denotes the overall mean of the data, and denotes the number of groups.
The "unexplained variance", or "within-group variability" is
where is the jth observation in the ith out of groups and is the overall sample size. This F-statistic follows the F-distribution with degrees of freedom and
under the null hypothesis. The statistic will be large if the
between-group variability is large relative to the within-group
variability, which is unlikely to happen if the population means of the groups all have the same value.
F Table: Level 5% Critical values, containing degrees of freedoms for both denominator and numerator ranging from 1-20
The result of the F test can be determined by comparing calculated F
value and critical F value with specific significance level (e.g. 5%).
The F table serves as a reference guide containing critical F values for
the distribution of the F-statistic under the assumption of a true null
hypothesis. It is designed to help determine the threshold beyond which
the F statistic is expected to exceed a controlled percentage of the
time (e.g., 5%) when the null hypothesis is accurate. To locate the
critical F value in the F table, one needs to utilize the respective
degrees of freedom. This involves identifying the appropriate row and
column in the F table that corresponds to the significance level being
tested (e.g., 5%).
How to use critical F values:
If the F statistic < the critical F value
Fail to reject null hypothesis
Reject alternative hypothesis
There is no significant differences among sample averages
The observed differences among sample averages could be reasonably caused by random chance itself
The result is not statistically significant
If the F statistic > the critical F value
Accept alternative hypothesis
Reject null hypothesis
There is significant differences among sample averages
The observed differences among sample averages could not be reasonably caused by random chance itself
The result is statistically significant
Note that when there are only two groups for the one-way ANOVA F-test, where t is the Student's statistic.
Advantages
Multi-group
Comparison Efficiency: Facilitating simultaneous comparison of multiple
groups, enhancing efficiency particularly in situations involving more
than two groups.
Clarity in Variance Comparison: Offering a straightforward
interpretation of variance differences among groups, contributing to a
clear understanding of the observed data patterns.
Versatility Across Disciplines: Demonstrating broad applicability
across diverse fields, including social sciences, natural sciences, and
engineering.
Disadvantages
Sensitivity
to Assumptions: The F-test is highly sensitive to certain assumptions,
such as homogeneity of variance and normality which can affect the
accuracy of test results.
Limited Scope to Group Comparisons: The F-test is tailored for
comparing variances between groups, making it less suitable for analyses
beyond this specific scope.
Interpretation Challenges: The F-test does not pinpoint specific
group pairs with distinct variances. Careful interpretation is
necessary, and additional post hoc tests are often essential for a more
detailed understanding of group-wise differences.
Multiple-comparison ANOVA problems
The F-test in one-way analysis of variance (ANOVA) is used to assess whether the expected values
of a quantitative variable within several pre-defined groups differ
from each other. For example, suppose that a medical trial compares four
treatments. The ANOVA F-test can be used to assess whether any
of the treatments are on average superior, or inferior, to the others
versus the null hypothesis that all four treatments yield the same mean
response. This is an example of an "omnibus" test, meaning that a
single test is performed to detect any of several possible differences.
Alternatively, we could carry out pairwise tests among the treatments
(for instance, in the medical trial example with four treatments we
could carry out six tests among pairs of treatments). The advantage of
the ANOVA F-test is that we do not need to pre-specify which treatments are to be compared, and we do not need to adjust for making multiple comparisons. The disadvantage of the ANOVA F-test is that if we reject the null hypothesis, we do not know which treatments can be said to be significantly different from the others, nor, if the F-test
is performed at level α, can we state that the treatment pair with the
greatest mean difference is significantly different at level α.
Consider two models, 1 and 2, where model 1 is 'nested' within model
2. Model 1 is the restricted model, and model 2 is the unrestricted
one. That is, model 1 has p1 parameters, and model 2 has p2 parameters, where p1 < p2,
and for any choice of parameters in model 1, the same regression curve
can be achieved by some choice of the parameters of model 2.
One common context in this regard is that of deciding whether a
model fits the data significantly better than does a naive model, in
which the only explanatory term is the intercept term, so that all
predicted values for the dependent variable are set equal to that
variable's sample mean. The naive model is the restricted model, since
the coefficients of all potential explanatory variables are restricted
to equal zero.
Another common context is deciding whether there is a structural
break in the data: here the restricted model uses all data in one
regression, while the unrestricted model uses separate regressions for
two different subsets of the data. This use of the F-test is known as
the Chow test.
The model with more parameters will always be able to fit the
data at least as well as the model with fewer parameters. Thus
typically model 2 will give a better (i.e. lower error) fit to the data
than model 1. But one often wants to determine whether model 2 gives a significantly better fit to the data. One approach to this problem is to use an F-test.
If there are n data points to estimate parameters of both models from, then one can calculate the F statistic, given by
where RSSi is the residual sum of squares of model i. If the regression model has been calculated with weights, then replace RSSi with χ2,
the weighted sum of squared residuals. Under the null hypothesis that
model 2 does not provide a significantly better fit than model 1, F will have an F distribution, with (p2−p1, n−p2) degrees of freedom. The null hypothesis is rejected if the F calculated from the data is greater than the critical value of the F-distribution for some desired false-rejection probability (e.g. 0.05). Since F is a monotone function of the likelihood ratio statistic, the F-test is a likelihood ratio test.
From Wikipedia, the free encyclopedia https://en.wikipedia.org/wiki/Gene_delivery Gene delivery is the process of introducing foreign genetic material, such as DNA or RNA, into host cells. Gene delivery must reach the genome of the host cell to induce gene expression.
Successful gene delivery requires the foreign gene delivery to remain
stable within the host cell and can either integrate into the genome or replicate independently of it. This requires foreign DNA to be synthesized as part of a vector, which is designed to enter the desired host cell and deliver the transgene to that cell's genome.
Vectors utilized as the method for gene delivery can be divided into
two categories, recombinant viruses and synthetic vectors (viral and
non-viral).
In complex multicellular eukaryotes (more specifically Weissmanists), if the transgene is incorporated into the host's germline cells, the resulting host cell can pass the transgene to its progeny. If the transgene is incorporated into somatic cells, the transgene will stay with the somatic cell line, and thus its host organism.
Gene delivery is a necessary step in gene therapy
for the introduction or silencing of a gene to promote a therapeutic
outcome in patients and also has applications in the genetic
modification of crops. There are many different methods of gene delivery
for various types of cells and tissues.
History
Viral
based vectors emerged in the 1980s as a tool for transgene expression.
In 1983, Albert Siegel described the use of viral vectors in plant
transgene expression although viral manipulation via cDNA cloning was
not yet available. The first virus to be used as a vaccine vector was the vaccinia virus in 1984 as a way to protect chimpanzees against hepatitis B. Non-viral gene delivery was first reported on in 1943 by Avery et al. who showed cellular phenotype change via exogenous DNA exposure.
Methods
Bacterial
transformation involves moving a gene from one bacteria to another. It
is integrated into the recipients plasmid. and can then be expressed by
the new host.
There are a variety of methods available to deliver genes to host
cells. When genes are delivered to bacteria or plants the process is
called transformation and when it is used to deliver genes to animals it is called transfection. This is because transformation has a different meaning in relation to animals, indicating progression to a cancerous state. For some bacteria no external methods are need to introduce genes as they are naturally able to take up foreign DNA.
Most cells require some sort of intervention to make the cell membrane
permeable to DNA and allow the DNA to be stably inserted into the hosts genome.
Chemical
Chemical
based methods of gene delivery can use natural or synthetic compounds
to form particles that facilitate the transfer of genes into cells.
These synthetic vectors have the ability to electrostatically bind DNA
or RNA and compact the genetic information to accommodate larger genetic
transfers. Chemical vectors usually enter cells by endocytosis and can protect genetic material from degradation.
Heat shock
One of the simplest method involves altering the environment of the cell and then stressing it by giving it a heat shock. Typically the cells are incubated in a solution containing divalentcations (often calcium chloride)
under cold conditions, before being exposed to a heat pulse. Calcium
chloride partially disrupts the cell membrane, which allows the
recombinant DNA to enter the host cell. It is suggested that exposing
the cells to divalent cations in cold condition may change or weaken the
cell surface structure, making it more permeable to DNA. The heat-pulse
is thought to create a thermal imbalance across the cell membrane,
which forces the DNA to enter the cells through either cell pores or the
damaged cell wall.
Calcium phosphate
Another simple methods involves using calcium phosphate to bind the DNA and then exposing it to cultured cells. The solution, along with the DNA, is encapsulated by the cells and a small amount of DNA can be integrated into the genome.
Liposomes and polymers
Liposomes and polymers
can be used as vectors to deliver DNA into cells. Positively charged
liposomes bind with the negatively charged DNA, while polymers can be
designed that interact with DNA. They form lipoplexes and polyplexes respectively, which are then up-taken by the cells. The two systems can also be combined. Polymer-based non-viral vectors uses polymers to interact with DNA and form polyplexes.
Nanoparticles
The use of engineered inorganic and organic nanoparticles is another non-viral approach for gene delivery.
Physical
Artificial
gene delivery can be mediated by physical methods which uses force to
introduce genetic material through the cell membrane.
Electroporation
Electroporators can be used to make the cell membrane permeable to DNA
Electroporation is a method of promoting competence. Cells are briefly shocked with an electric field of 10-20 kV/cm,
which is thought to create holes in the cell membrane through which the
plasmid DNA may enter. After the electric shock, the holes are rapidly
closed by the cell's membrane-repair mechanisms.
Biolistics
A gene gun uses biolistics to insert DNA into cells
Another method used to transform plant cells is biolistics, where particles of gold or tungsten are coated with DNA and then shot into young plant cells or plant embryos. Some genetic material enters the cells and transforms them. This method can be used on plants that are not susceptible to Agrobacterium infection and also allows transformation of plant plastids.
Plants cells can also be transformed using electroporation, which uses
an electric shock to make the cell membrane permeable to plasmid DNA.
Due to the damage caused to the cells and DNA the transformation
efficiency of biolistics and electroporation is lower than agrobacterial
transformation.
Sonoporation is the transient permeation of cell membranes assisted by ultrasound, typically in the presence of gas microbubbles. Sonoporation allows for the entry of genetic material into cells.
Photoporation
Photoporation is when laser pulses are used to create pores in a cell membrane to allow entry of genetic material.
Magnetofection
Magnetofection uses magnetic particles complexed with DNA and an external magnetic field concentrate nucleic acid particles into target cells.
Hydroporation
A hydrodynamic capillary effect can be used to manipulate cell permeability.
In plants the DNA is often inserted using Agrobacterium-mediated recombination, taking advantage of the Agrobacteriums T-DNA sequence that allows natural insertion of genetic material into plant cells. Plant tissue are cut into small pieces and soaked in a fluid containing suspended Agrobacterium. The bacteria will attach to many of the plant cells exposed by the cuts. The bacteria uses conjugation to transfer a DNA segment called T-DNA
from its plasmid into the plant. The transferred DNA is piloted to the
plant cell nucleus and integrated into the host plants genomic DNA.The
plasmid T-DNA is integrated semi-randomly into the genome of the host cell.
By modifying the plasmid to express the gene of interest,
researchers can insert their chosen gene stably into the plants genome.
The only essential parts of the T-DNA are its two small (25 base pair)
border repeats, at least one of which is needed for plant
transformation. The genes to be introduced into the plant are cloned into a plant transformation vector that contains the T-DNA region of the plasmid. An alternative method is agroinfiltration.
Viral delivery
Foreign DNA being transduced into the host cell through an adenovirus vector.
Virus
mediated gene delivery utilizes the ability of a virus to inject its
DNA inside a host cell and takes advantage of the virus' own ability to
replicate and implement their own genetic material. Viral methods of
gene delivery are more likely to induce an immune response, but they
have high efficiency. Transduction
is the process that describes virus-mediated insertion of DNA into the
host cell. Viruses are a particularly effective form of gene delivery
because the structure of the virus prevents degradation via lysosomes of the DNA it is delivering to the nucleus of the host cell. In gene therapy a gene that is intended for delivery is packaged into a replication-deficient viral particle to form a viral vector.
Viruses used for gene therapy to date include retrovirus, adenovirus,
adeno-associated virus and herpes simplex virus. However, there are
drawbacks to using viruses to deliver genes into cells. Viruses can only
deliver very small pieces of DNA into the cells, it is labor-intensive
and there are risks of random insertion sites, cytopathic effects and mutagenesis.
Viral vector based gene delivery uses a viral vector
to deliver genetic material to the host cell. This is done by using a
virus that contains the desired gene and removing the part of the
viruses genome that is infectious. Viruses are efficient at delivering genetic material to the host cell's nucleus, which is vital for replication.
RNA-based viral vectors
RNA-based
viruses were developed because of the ability to transcribe directly
from infectious RNA transcripts. RNA vectors are quickly expressed and
expressed in the targeted form since no processing is required [source
needed]. Retroviral vectors include oncoretroviral, lentiviral and human foamy virus
are RNA-based viral vectors that reverse transcript and integrated into
the host genome, permits long-term transgene expression.
Several of the methods used to facilitate gene delivery have applications for therapeutic purposes. Gene therapy
utilizes gene delivery to deliver genetic material with the goal of
treating a disease or condition in the cell. Gene delivery in
therapeutic settings utilizes non-immunogenic vectors capable of cell specificity that can deliver an adequate amount of transgene expression to cause the desired effect.
Advances in genomics have enabled a variety of new methods and gene targets to be identified for possible applications. DNA microarrays used in a variety of next-gen sequencing can identify thousands of genes simultaneously, with analytical software looking at gene expression patterns, and orthologous genes in model species to identify function.
This has allowed a variety of possible vectors to be identified for use
in gene therapy. As a method for creating a new class of vaccine, gene
delivery has been utilized to generate a hybrid biosynthetic vector to deliver a possible vaccine. This vector overcomes traditional barriers to gene delivery by combining E. coli with a synthetic polymer to create a vector that maintains plasmid DNA while having an increased ability to avoid degradation by target cell lysosomes.
Cloud storage is a model of computer data storage in which data, said to be on "the cloud", is stored remotely in logical pools and is accessible to users over a network, typically the Internet. The physical storage spans multiple servers (sometimes in multiple locations), and the physical environment is typically owned and managed by a cloud computing provider. These cloud storage providers are responsible for keeping the data available and accessible,
and the physical environment secured, protected, and running. People
and organizations buy or lease storage capacity from the providers to
store user, organization, or application data.
Cloud computing is believed to have been invented by J. C. R. Licklider in the 1960s with his work on ARPANET to connect people and data from anywhere at any time.
In 1983, CompuServe offered its consumer users a small amount of disk space that could be used to store any files they chose to upload.
In 1994, AT&T
launched PersonaLink Services, an online platform for personal and
business communication and entrepreneurship. The storage was one of the
first to be all web-based, and referenced in their commercials as, "you
can think of our electronic meeting place as the cloud." Amazon Web Services introduced their cloud storage service Amazon S3 in 2006, and has gained widespread recognition and adoption as the storage supplier to popular services such as SmugMug, Dropbox, and Pinterest. In 2005, Box announced an online file sharing and personal cloud content management service for businesses.
Architecture
A high level architecture of cloud storage
Cloud storage is based on highly virtualized infrastructure and is like broader cloud computing in terms of interfaces, near-instant elasticity and scalability, multi-tenancy, and metered resources. Cloud storage services can be used from an off-premises service (Amazon S3) or deployed on-premises (ViON Capacity Services).
There are three types of cloud storage: a hosted object storage service, file storage, and block storage. Each of these cloud storage types offer their own unique advantages.
Examples of object storage services that can be hosted and deployed with cloud storage characteristics include Amazon S3, Oracle Cloud Storage and Microsoft Azure Storage, object storage software like Openstack Swift, object storage systems like EMC Atmos, EMC ECS and Hitachi Content Platform, and distributed storage research projects like OceanStore and VISION Cloud.
Examples of file storage services include Amazon Elastic File System (EFS) and Qumulo Core, used for applications that need access to shared files and require a file system. This storage is often supported with a Network Attached Storage (NAS) server, used for large content repositories, development environments, media stores, or user home directories.
A block storage service like Amazon Elastic Block Store
(EBS) is used for other enterprise applications like databases and
often require dedicated, low latency storage for each host. This is
comparable in certain respects to direct attached storage (DAS) or a storage area network (SAN).
Companies need only pay for the storage they actually use, typically an average of consumption during a month, quarter, or year. This does not mean that cloud storage is less expensive, only that it incurs operating expenses rather than capital expenses.
Businesses using cloud storage can cut their energy consumption by up to 70% making them a more green business.
Organizations can choose between off-premises and on-premises cloud
storage options, or a mixture of the two options, depending on relevant
decision criteria that is complementary to initial direct cost savings
potential; for instance, continuity of operations (COOP), disaster
recovery (DR), security (PII, HIPAA, SARBOX, IA/CND), and records
retention laws, regulations, and policies.
Storage availability and data protection
is intrinsic to object storage architecture, so depending on the
application, the additional technology, effort and cost to add
availability and protection can be eliminated.
Storage maintenance tasks, such as purchasing additional storage
capacity, are offloaded to the responsibility of a service provider.
Cloud storage provides users with immediate access to a broad range
of resources and applications hosted in the infrastructure of another
organization via a web service interface.
Cloud storage can be used for copying virtual machine images
from the cloud to on-premises locations or to import a virtual machine
image from an on-premises location to the cloud image library. In
addition, cloud storage can be used to move virtual machine images
between user accounts or between data centers.
Cloud storage can be used as natural disaster proof backup, as
normally there are 2 or 3 different backup servers located in different
places around the globe.
Cloud storage can be mapped as a local drive with the WebDAV protocol. It can function as a central file server for organizations with multiple office locations.
When data has been distributed it is stored at more locations
increasing the risk of unauthorized physical access to the data. For
example, in cloud based architecture, data is replicated and moved
frequently so the risk of unauthorized data recovery increases
dramatically. Such as in the case of disposal of old equipment, reuse of
drives, reallocation of storage space. The manner that data is
replicated depends on the service level a customer chooses and on the
service provided. When encryption is in place it can ensure
confidentiality. Crypto-shredding can be used when disposing of data (on a disk).
The number of people with access to the data who could be
compromised (e.g., bribed, or coerced) increases dramatically. A single
company might have a small team of administrators, network engineers,
and technicians, but a cloud storage company will have many customers
and thousands of servers, therefore a much larger team of technical
staff with physical and electronic access to almost all of the data at
the entire facility or perhaps the entire company.
Decryption keys that are kept by the service user, as opposed to the
service provider, limit access to data by service provider employees. As
for sharing multiple data in the cloud with multiple users, a large
number of keys has to be distributed to users via secure channels for
decryption, also it has to be securely stored and managed by the users
in their devices. Storing these keys requires rather expensive secure
storage. To overcome that, key-aggregate cryptosystem can be used.
It increases the number of networks over which the data travels.
Instead of just a local area network (LAN) or storage area network
(SAN), data stored on a cloud requires a WAN (wide area network) to
connect them both.
By sharing storage and networks with many other users/customers it
is possible for other customers to access your data. Sometimes because
of erroneous actions, faulty equipment, a bug and sometimes because of
criminal intent. This risk applies to all types of storage and not only
cloud storage. The risk of having data read during transmission can be
mitigated through encryption technology. Encryption in transit protects
data as it is being transmitted to and from the cloud service.
Encryption at rest protects data that is stored at the service
provider. Encrypting data in an on-premises cloud service on-ramp system
can provide both kinds of encryption protection.
There are several options available to avoid security issues. One
option is to use a private cloud instead of a public cloud. Another
option is to ingest data in an encrypted format where the key is held
within the on-premise infrastructure. To this end, access is often by
use of on-premise cloud storage gateways that have options to encrypt the data prior of transfer.
Companies are not permanent and the services and products they
provide can change. Outsourcing data storage to another company needs
careful investigation and nothing is ever certain. Contracts set in
stone can be worthless when a company ceases to exist or its
circumstances change. Companies can:
Go bankrupt.
Expand and change their focus.
Be purchased by other larger companies.
Be purchased by a company headquartered in or move to a country that negates compliance with export restrictions and thus necessitates a move.
Suffer an irrecoverable disaster.
Accessibility
Performance
for outsourced storage is likely to be lower than local storage,
depending on how much a customer is willing to spend for WAN bandwidth
Reliability and availability depends on wide area network
availability and on the level of precautions taken by the service
provider. Reliability should be based on hardware as well as various
algorithms used.
Limitations of Service Level Agreements
Typically, cloud storage Service Level Agreements
(SLAs) do not encompass all forms of service interruptions. Exclusions
typically include planned maintenance, downtime resulting from external
factors such as network issues, human errors like misconfigurations, natural disasters, force majeure events, or security breaches.
Typically, customers bear the responsibility of monitoring SLA
compliance and must file claims for any unmet SLAs within a designated
timeframe. Customers should be aware of how deviations from SLAs are
calculated, as these parameters may vary by other services offered
within the same provider. These requirements can place a considerable
burden on customers. Additionally, SLA percentages and conditions can
differ across various services within the same provider, with some
services lacking any SLA altogether. In cases of service interruptions
due to hardware failures in the cloud provider, service providers
typically do not offer monetary compensation. Instead, eligible users
may receive credits as outlined in the corresponding SLA.
Other concerns
Security of stored data and data in transit may be a concern when storing sensitive data at a cloud storage provider
Users with specific records-keeping requirements, such as public
agencies that must retain electronic records according to statute, may
encounter complications with using cloud computing and storage. For
instance, the U.S. Department of Defense designated the Defense
Information Systems Agency (DISA) to maintain a list of records
management products that meet all of the records retention, personally identifiable information (PII), and security (Information Assurance; IA) requirements
Cloud storage is a rich resource for both hackers and national security agencies. Because the cloud holds data from many different users and organizations, hackers see it as a very valuable target.
Piracy and copyright infringement may be enabled by sites that
permit filesharing. For example, the CodexCloud ebook storage site has
faced litigation from the owners of the intellectual property uploaded
and shared there, as have the Grooveshark and YouTube sites it has been compared to.
The legal aspect, from a regulatory compliance standpoint, is of
concern when storing files domestically and especially internationally.
The resources used to produce large data centers, especially those
needed to power them, is causing nations to drastically increase their
energy production. This can lead to further climate damaging
implications.
Hybrid cloud storage is a term for a storage infrastructure that uses
a combination of on-premises storage resources with cloud storage. The
on-premises storage is usually managed by the organization, while the
public cloud storage provider is responsible for the management and
security of the data stored in the cloud. Hybrid cloud storage can be implemented by an on-premises cloud storage gateway
that presents a file system or object storage interface which the users
can access in the same way they would access a local storage system.
The cloud storage gateway transparently transfers the data to and from
the cloud storage service, providing low latency access to the data
through a local cache.
Hybrid cloud storage can be used to supplement an organization's
internal storage resources, or it can be used as the primary storage
infrastructure. In either case, hybrid cloud storage can provide
organizations with greater flexibility and scalability than traditional
on-premises storage infrastructure.
There are several benefits to using hybrid cloud storage, including the ability to cache frequently used data on-site for quick access, while inactive cold data
is stored off-site in the cloud. This can save space, reduce storage
costs and improve performance. Additionally, hybrid cloud storage can
provide organizations with greater redundancy and fault tolerance, as
data is stored in both on-premises and cloud storage infrastructure.
CRISPR-Cas9 gene editing quickly decimated two caged populations of malaria-bearing mosquitoes (Anopheles gambiae) in a recent study, introducing a new way to solve an age-old problem. But the paper describing the feat in NatureBiotechnology
had a broader meaning regarding the value of basic research. It also
prompts us to consider the risks and rewards of releasing such a
powerful gene drive into the wild.
Instead of altering a gene affecting production of a reproductive
hormone, the editing has a more fundamental target: a gene that
determines sex. The work was done by Andrea Crisanti and colleagues at
Imperial College London. Their clever use of the ancient insect mutation
doublesex rang a bell for me — I’d used a fruit fly version in grad
school.
Blast from the past
In the days before genome sequencing, geneticists made mutants in
model organisms like fruit flies to discover gene functions. I worked on
mutations that mix up body parts.
To make mutants, I’d poison larvae or schlep them, squiggling through
the goop in their old-fashioned milk bottles, from the lab at Indiana
University in Bloomington to the children’s cancer center in
Indianapolis and zap them with x-rays. Crossing the grown-up larvae to
flies that carried already-known mutations would reveal whether we’d
induced anything of interest in their offspring. One of the mutations we
used in these genetic screens was doublesex.
A suite of genes determines sex in insects, not just inheriting an X
or Y chromosome. Doublesex acts at a developmental crossroads to select
the pathway towards femaleness or maleness. When the gene is missing or
mutant, flies display a mishmash of sexual parts and altered behavior.
Males with doublesex mutations “are impaired in their willingness to
court females,” according to one study, and when they do seek sex, they can’t hum appropriately and “court other males at abnormally high levels.”
Back then, we used doublesex as a tool to identify new mutations. We
never imagined it being used to prevent an infectious disease that
causes nearly half a million deaths a year, mostly among young children.
A gene drive skews inheritance, destroying fertility
In grad school, we bred flies for many generations to select a trait,
because a mutation in a carrier passes to only half the offspring. A
gene drive speeds things by messing with Mendel’s first law, which says
that at each generation, each member of a pair of gene variants
(alleles) gets sent into a sperm or egg with equal frequency.
Austin Burt, a co-author of the new paper, introduced the idea of a gene drive in 2003,
pre-CRISPR. The intervention uses a version of natural DNA repair that
snips out one copy of a gene and replaces it with a copy of whatever
corresponding allele is on the paired chromosome. Imagine dance
partners, removing one, and inserting an identical twin of the other.
In the language of genetics, a gene drive can turn a heterozygote (2
different copies of a gene) into a homozygote (2 identical copies).
In 2014,
Kevin Esvelt, George Church, and their colleagues at Harvard suggested
how to use CRISPR-Cas9 gene editing to speed a gene drive. It made so
much sense that in 2016, the National Academies of Sciences,
Engineering, and Medicine issued a report urging caution while endorsing continued laboratory experimentation and limited field trials of gene drives.
The idea to genetically cripple mosquito reproduction isn’t new. But a
CRISPRed gene drive to do so would be fast, leading to mass sterility
within a few generations, with the population plummeting towards
extinction. And doublesex is an inspired target. It’s so vital that only
one variant in Anopheles gambiae is known in the wild — any
other mutations so impair the animals that they and their genes don’t
persist. That’s why the gene can’t mutate itself back into working, like
bacteria developing antibiotic resistance. For doublesex, resistance is
futile.
Harnessing doublesex
The doublesex gene consists of 7 protein-encoding exons and the
introns that separate them. The gene is alternatively spliced:
mosquitoes keeping exon 5 become females and those that jettison the
exon develop as males.
The researchers injected mosquito embryos with CRISPR-Cas9 engineered
to harpoon the boundary between intron 4 and exon 5 of the doublesex
gene. They added genetic instructions for red fluorescent protein on the
Y chromosome to mark male gonads, so the researchers could distinguish
the sexes.
The modified female mosquitoes were weird. They sported male clasper
organs rotated the wrong way and lacked parts of the female sex organ
repertoire. They had feathery male-like “plumose antennae,” neither
ovaries nor female sperm holders, yet male accessory glands and in some
individuals “rudimentary pear-shaped organs resembling unstructured
testes.” Most importantly, the doctored females couldn’t bite or suck up
blood meals.
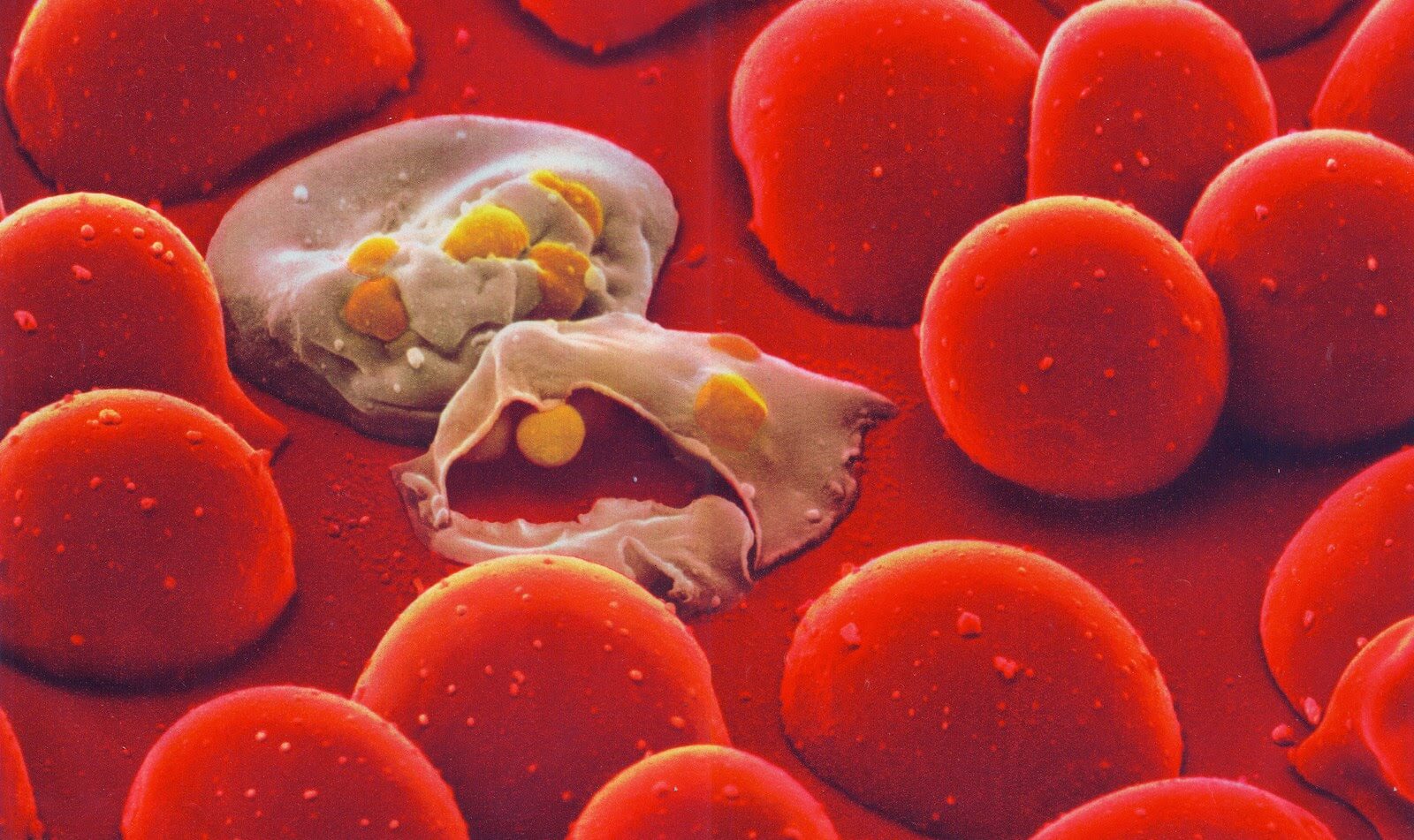
Malaria parasites infect two blood cells. Credit: Lennart Nilsson / Scanpix
The researchers set up two cages, each housing 300 females with
normal doublesex genes, 150 normal males, and 150 males that had one
copy of normal doublesex and one modified copy, called CRISPRh. Then the
insects mated. (For a scintillating description of fly sex see A Fruit Fly Love Story: The Making of a Mutant.)
Within 7 generations in one cage and 11 in the other, all the female
flies had CRISPRh and couldn’t mate. Because males with one copy of
CRISPRh are fertile, the populations chugged along until the gene drive
rendered all the females homozygous. With two copies of the modified
doublesex gene, they couldn’t eat or mate.
Next steps
Gene editing of doublesex presents a question of balance. The
investigators dub it “an Achilles heel” common to many insect species,
yet at the same time, the DNA sequences are species-specific enough to
not spread to other types of insects. A gene drive that kills off bees
or aphids, for example, would be disastrous.
Next will come experiments in “large confined spaces” more like
nature. Cooped up, mosquitoes don’t have much to do besides breed. In a
more natural setting, they’d have to compete for resources and mates,
confront changing conditions, and avoid being eaten. But computer
simulations suggest that adding these stresses would only slightly slow
spread of the gene drive.
Field tests are 5 to 10 years in the future, the researchers say. Dr.
Burt estimates that releasing a few hundred doctored mosquitoes at a
time, into selected African villages, might knock down populations
sufficiently to wipe them out, even over a wider range. Local
eradication of malaria would take about 15 years once a gene drive
begins, he projects.
Will nature find a way around gene drives?
What about “unforeseen consequences” of unleashing a gene drive to
vanquish malaria-bearing mosquitoes? To quote fictional mathematician
Ian Malcolm in discussing the cloned dinosaurs of Jurassic Park, “Your scientists were so preoccupied with whether they could, they didn’t stop to think if they should.”
We’re past the “could” stage with a doublesex-mediated gene drive
against the mosquitoes. But perhaps we shouldn’t ignore the history of
biotechnology. Even though no superbugs or triple-headed purple monsters
have escaped from recombinant DNA labs since self-policing began at the Asilomar meeting in 1975, pollen from genetically modified crops has wafted well beyond treated fields. Sometimes, as Dr. Malcolm said, “life, uh, finds a way.”
Yet the severity and persistence of malaria may justify the risk of unforeseen consequences in developing a gene drive.
About 216 million malaria cases occurred globally in 2016, with an
estimated 445,000 deaths, according to the WHO’s World Malaria Report
2017, which states that “after an unprecedented period of success in
global malaria control, progress has stalled.” Said Dr. Crisanti, “2016
marked the first time in over two decades that malaria cases did not
fall despite huge efforts and resources, suggesting we need more tools
in the fight. This breakthrough shows that a gene drive can work,
providing hope in the fight against a disease that has plagued mankind
for centuries.”
Just like recombinant DNA entered the clinic in 1982 with FDA
approval of human insulin produced in bacteria, the first gene drive,
whatever it may deliver, could open the door for many others, just as
dozens of drugs are now based on combining genes of different species.
Doublesex, the mutation that I used in graduate school to screen new
mutations, is one gene of thousands in just that one species. If and
when gene drives are validated, the possibilities to limit or eradicate
infectious diseases are almost limitless, thanks to the genetic
toolboxes provided from decades of basic research.
Ricki Lewis has a PhD in genetics and is a science writer and
author of several human genetics books. She is an adjunct professor for
the Alden March Bioethics Institute at Albany Medical College. Follow
her at her website or Twitter @rickilewis
This story was originally published at the GLP on October 2, 2018.
Types of mutations that can be introduced by random, site-directed, combinatorial, or insertional mutagenesis
In molecular biology, mutagenesis is an important laboratory technique whereby DNA mutations are deliberately engineered to produce libraries of mutant genes, proteins, strains of bacteria, or other genetically modified organisms.
The various constituents of a gene, as well as its regulatory elements
and its gene products, may be mutated so that the functioning of a
genetic locus, process, or product can be examined in detail. The
mutation may produce mutant proteins with interesting properties or
enhanced or novel functions that may be of commercial use. Mutant
strains may also be produced that have practical application or allow
the molecular basis of a particular cell function to be investigated.
Many methods of mutagenesis exist today. Initially, the kind of
mutations artificially induced in the laboratory were entirely random
using mechanisms such as UV irradiation. Random mutagenesis cannot
target specific regions or sequences of the genome; however, with the
development of site-directed mutagenesis, more specific changes can be made. Since 2013, development of the CRISPR/Cas9 technology, based on a prokaryotic viral defense system, has allowed for the editing or mutagenesis of a genome in vivo.
Site-directed mutagenesis has proved useful in situations that random
mutagenesis is not. Other techniques of mutagenesis include
combinatorial and insertional mutagenesis. Mutagenesis that is not
random can be used to clone DNA, investigate the effects of mutagens, and engineer proteins.
It also has medical applications such as helping immunocompromised
patients, research and treatment of diseases including HIV and cancers,
and curing of diseases such as beta thalassemia.
Random mutagenesis
How DNA libraries generated by random mutagenesis
sample sequence space. The amino acid substituted into a given position
is shown. Each dot or set of connected dots is one member of the
library. Error-prone PCR randomly mutates some residues to other amino
acids. Alanine scanning replaces each residue of the protein with
alanine, one-by-one. Site saturation substitutes each of the 20 possible
amino acids (or some subset of them) at a single position, one-by-one.
Early approaches to mutagenesis relied on methods which produced
entirely random mutations. In such methods, cells or organisms are
exposed to mutagens such as UV radiation or mutagenic chemicals, and mutants with desired characteristics are then selected. Hermann Muller discovered in 1927 that X-rays can cause genetic mutations in fruit flies, and went on to use the mutants he created for his studies in genetics. For Escherichia coli, mutants may be selected first by exposure to UV radiation, then plated onto an agar medium. The colonies formed are then replica-plated, one in a rich medium,
another in a minimal medium, and mutants that have specific nutritional
requirements can then be identified by their inability to grow in the
minimal medium. Similar procedures may be repeated with other types of
cells and with different media for selection.
A number of methods for generating random mutations in specific proteins were later developed to screen for mutants with interesting or improved properties. These methods may involve the use of doped nucleotides in oligonucleotide synthesis, or conducting a PCR
reaction in conditions that enhance misincorporation of nucleotides
(error-prone PCR), for example by reducing the fidelity of replication
or using nucleotide analogues. A variation of this method for integrating non-biased mutations in a gene is sequence saturation mutagenesis. PCR products which contain mutation(s) are then cloned into an expression vector and the mutant proteins produced can then be characterised.
In a European Union law (as 2001/18 directive), this kind of mutagenesis may be used to produce GMOs but the products are exempted from regulation: no labeling, no evaluation.
Prior to the development site-directed mutagenesis techniques, all
mutations made were random, and scientists had to use selection for the
desired phenotype to find the desired mutation. Random mutagenesis
techniques has an advantage in terms of how many mutations can be
produced; however, while random mutagenesis can produce a change in
single nucleotides, it does not offer much control as to which
nucleotide is being changed.
Many researchers therefore seek to introduce selected changes to DNA in
a precise, site-specific manner. Early attempts uses analogs of
nucleotides and other chemicals were first used to generate localized point mutations. Such chemicals include aminopurine, which induces an AT to GC transition, while nitrosoguanidine, bisulfite, and N4-hydroxycytidine may induce a GC to AT transition.
These techniques allow specific mutations to be engineered into a
protein; however, they are not flexible with respect to the kinds of
mutants generated, nor are they as specific as later methods of
site-directed mutagenesis and therefore have some degree of randomness.
Other technologies such as cleavage of DNA at specific sites on the
chromosome, addition of new nucleotides, and exchanging of base pairs it
is now possible to decide where mutations can go.
Simplified
diagram of the site directed mutagenic technique using pre-fabricated
oligonucleotides in a primer extension reaction with DNA polymerase
Current techniques for site-specific mutation originates from the
primer extension technique developed in 1978. Such techniques commonly
involve using pre-fabricated mutagenic oligonucleotides in a primer extension reaction with DNA polymerase. This methods allows for point mutation or deletion or insertion
of small stretches of DNA at specific sites. Advances in methodology
have made such mutagenesis now a relatively simple and efficient
process.
Newer and more efficient methods of site directed mutagenesis are
being constantly developed. For example, a technique called "Seamless
ligation cloning extract" (or SLiCE for short) allows for the cloning of
certain sequences of DNA within the genome, and more than one DNA
fragment can be inserted into the genome at once.
Site directed mutagenesis allows the effect of specific mutation
to be investigated. There are numerous uses; for example, it has been
used to determine how susceptible certain species were to chemicals that
are often used In labs. The experiment used site directed mutagenesis
to mimic the expected mutations of the specific chemical. The mutation
resulted in a change in specific amino acids and the effects of this
mutation were analyzed.
Site
saturation mutagenesis is a type of site-directed mutagenesis. This
image shows the saturation mutagenesis of a single position in a
theoretical 10-residue protein. The wild type version of the protein is
shown at the top, with M representing the first amino acid methionine,
and * representing the termination of translation. All 19 mutants of the
isoleucine at position 5 are shown below.
The site-directed approach may be done systematically in such techniques as alanine scanning mutagenesis, whereby residues are systematically mutated to alanine in order to identify residues important to the structure or function of a protein. Another comprehensive approach is site saturation mutagenesis where one codon or a set of codons may be substituted with all possible amino acids at the specific positions.
Combinatorial mutagenesis
Combinatorial
mutagenesis is a site-directed protein engineering technique whereby
multiple mutants of a protein can be simultaneously engineered based on
analysis of the effects of additive individual mutations. It provides a useful method to assess the combinatorial effect of a large number of mutations on protein function. Large numbers of mutants may be screened for a particular characteristic by combinatorial analysis.
In this technique, multiple positions or short sequences along a DNA
strand may be exhaustively modified to obtain a comprehensive library of
mutant proteins.
The rate of incidence of beneficial variants can be improved by
different methods for constructing mutagenesis libraries. One approach
to this technique is to extract and replace a portion of the DNA
sequence with a library of sequences containing all possible
combinations at the desired mutation site. The content of the inserted
segment can include sequences of structural significance, immunogenic
property, or enzymatic function. A segment may also be inserted randomly
into the gene in order to assess structural or functional significance
of a particular part of a protein.
The insertion of one or more base pairs, resulting in DNA mutations, is also known as insertional mutagenesis.
Engineered mutations such as these can provide important information in
cancer research, such as mechanistic insights into the development of
the disease. Retroviruses and transposons are the chief instrumental
tools in insertional mutagenesis. Retroviruses, such as the mouse
mammory tumor virus and murine leukemia virus, can be used to identify
genes involved in carcinogenesis and understand the biological pathways
of specific cancers.
Transposons, chromosomal segments that can undergo transposition, can
be designed and applied to insertional mutagenesis as an instrument for
cancer gene discovery.
These chromosomal segments allow insertional mutagenesis to be applied
to virtually any tissue of choice while also allowing for more
comprehensive, unbiased depth in DNA sequencing.
Researchers have found four mechanisms of insertional mutagenesis
that can be used on humans. the first mechanism is called enhancer
insertion. Enhancers boost transcription of a particular gene by
interacting with a promoter of that gene. This particular mechanism was
first used to help severely immunocompromised patients I need of bone
marrow. Gammaretroviruses carrying enhancers were then inserted into
patients. The second mechanism is referred to as promoter insertion.
Promoters provide our cells with the specific sequences needed to begin
translation. Promoter insertion has helped researchers learn more about
the HIV virus. The third mechanism is gene inactivation. An example of
gene inactivation is using insertional mutagenesis to insert a
retrovirus that disrupts the genome of the T cell in leukemia patients
and giving them a specific antigen called CAR allowing the T cells to
target cancer cells. The final mechanisms is referred to as mRNA 3' end
substitution. Our genes occasionally undergo point mutations causing
beta-thalassemia that interrupts red blood cell function. To fix this
problem the correct gene sequence for the red blood cells are introduced
and a substitution is made.
Homologous recombination
Homologous recombination
can be used to produce specific mutation in an organism. Vector
containing DNA sequence similar to the gene to be modified is introduced
to the cell, and by a process of recombination replaces the target gene
in the chromosome. This method can be used to introduce a mutation or
knock out a gene, for example as used in the production of knockout mice.
Since 2013, the development of CRISPR-Cas9
technology has allowed for the efficient introduction of different
types of mutations into the genome of a wide variety of organisms. The
method does not require a transposon insertion site, leaves no marker,
and its efficiency and simplicity has made it the preferred method for genome editing.
Gene synthesis
As the cost of DNA oligonucleotide synthesis falls, artificial synthesis of a complete gene
is now a viable method for introducing mutations into a gene. This
method allows for extensive mutation at multiple sites, including the
complete redesign of the codon usage of a gene to optimise it for a
particular organism.