In the wild uproar around an
experiment in China that claimed to have created twin girls whose genes
were altered to protect them from HIV, there’s something worth
knowing—research to improve the next generation of humans is happening
in the US, too.
In fact, it’s about to happen at Harvard University.
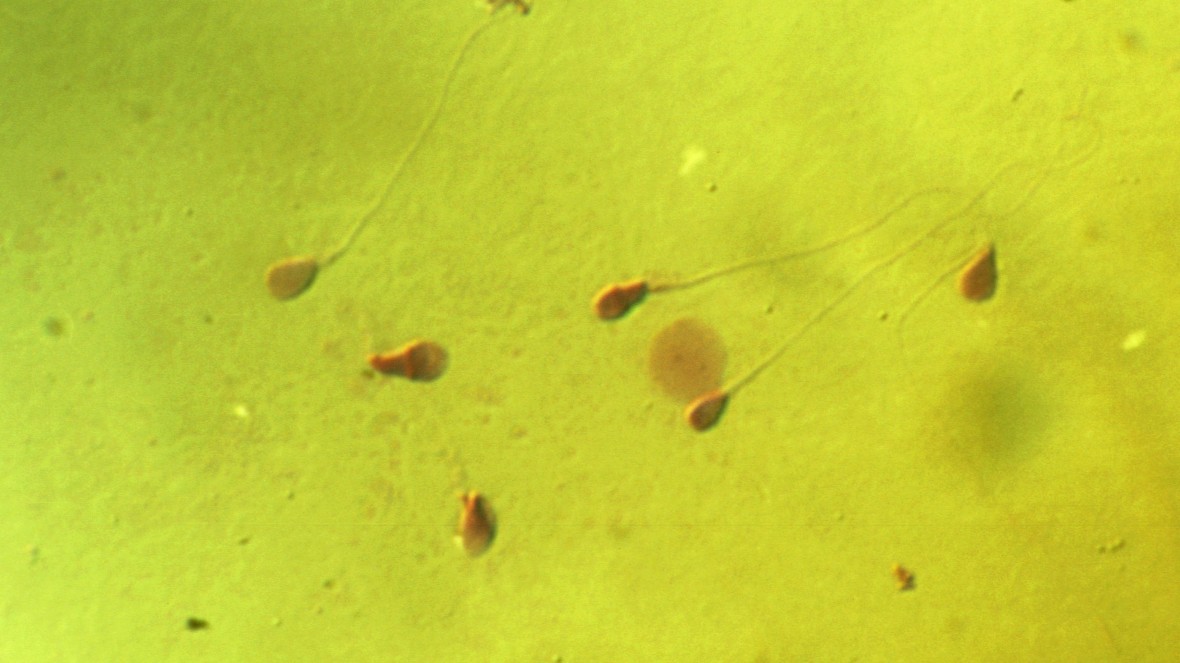
At the school’s Stem Cell Institute, IVF
doctor and scientist Werner Neuhausser says he plans to begin using
CRISPR, the gene-editing tool, to change the DNA code inside sperm
cells. The objective: to show whether it is possible to create IVF
babies with a greatly reduced risk of Alzheimer’s disease later in life.
To be clear, there are no embryos involved—no attempt to make a
baby. Not yet. Instead, the researchers are practicing how to change the
DNA in sperm collected from Boston IVF, a large national
fertility-clinic network. This is still very basic, and unpublished,
research.
Yet in its purpose the project is similar to the work undertaken in
China and raises the same fundamental question: does society want
children with genes tailored to prevent disease?
Since Sunday, when the CRISPR babies claims was made public, medical bodies and experts have ferociously condemned He Jiankui, the Chinese scientist responsible. There is evidence
his experiments—now halted—were carried forward in an unethical,
deceptive manner that may have endangered the children he created.
China’s vice minister of science and technology, Xu Nanping, said the
effort “crossed the line of morality and ethics and was shocking and
unacceptable.”
Amid the condemnation, though, it was easy to lose track of what
the key experts were saying. Technology to alter heredity is for real.
It is improving very quickly, it has features that will make it safe,
and much wider exploratory use to create children could be justified
soon.
That was the message delivered at a gene-editing summit in Hong
Kong on Wednesday, November 28, by Harvard Medical School dean George
Daley, just ahead of He’s own dramatic appearance on the stage.
Astounding some listeners, the Harvard doctor and stem-cell
researcher didn’t condemn He but instead characterized the Chinese
actions as a wrong turn on the right path (see video).
“The fact that it is possible that the first instance of human
germ-line editing came forward as a misstep should in no way lead us to
stick our heads in the sand,” Daley said. “It’s time to ... start
outlining what an actual pathway for clinical translation would be.”
IVF doctor and bench scientist Werner Neuhausser is exploring applications of gene editing,
Courtesy of Werner Neuhausser
By germ-line editing, Daley means editing sperm, eggs, or
embryos—anything that, if you alter its DNA, could convey the change to
future generations. While other voices demanded a ban on germ-line
editing, Daley and the other members of the summit’s leadership defended
it. Their final statement said medicine’s daring and troubled project
to modify humans in an IVF dish should move forward.
“It’s absolutely clear this is a transformative scientific technology with the power for great medical use.” Daley said.
Harvard project
Germ-line editing could be used, Daley said—and potentially should be
used—to shape the health of tomorrow’s kids. By editing germ cells, it
will be possible to remove mutations that cause childhood cancer or
cystic fibrosis. Other genetic edits could endow children with
protection against common diseases. On Daley’s list of potentially
acceptable genes to edit was CCR5, the very gene that He altered in the
twins.
At Harvard, Neuhausser says he and a research fellow, Denis
Vaughan, will in the next few weeks begin editing sperm to change a gene
called ApoE, which is strongly linked to Alzheimer’s risk. A person who
inherits two copies of the high-risk version of the gene has about a
60% lifetime risk of getting Alzheimer’s.
Neuhausser, an Austrian fertility doctor who came to the US to do
his research and practice at Boston IVF, predicts that in not so many
years, embryos will be deeply analyzed, selected, and in some cases
altered with CRISPR before they are used to create a pregnancy. “In the
future, people will go to clinics and get their genomes tested, and have
the healthiest baby they can have,” he says. “I think the whole field
will switch from fertility to disease prophylaxis”—preventing illness.
To alter the DNA inside sperm cells, the team is using a clever new
version of CRISPR called base editing, developed by another
Harvard scientist, David Liu. Instead of breaking open the double helix,
base editing can flip a single genetic letter from, say, G to A. One
such molecular tweak is enough to turn a the riskiest version of the
ApoE gene into the least risky.
“It’s one letter, G to A. You take it from risk to non-risk,” says Neuhausser.
Backlash
You know what is risky? Speaking to journalists these days
about how you are altering the germ line. But Neuhausser hasn’t ever
shied from telling me what’s going on in the lab.
Harvard Medical School dean George Q. Daley is defending a new form of medicine in which children's DNA is changed.
Harvard
And lack of transparency is one reason the Chinese experiment is so
troubling. It was done secretly, and ignored China’s rules forbidding
such work. “The problem is that it’s going to make things much harder
for everyone else following the rules if you jump so far ahead without
proper approvals,” says Neuhausser. “That is the main concern. I don’t
think the research is controversial, but everyone agrees it should be
kept away from patients for now.”
The debate has already caught the attention of regulators. Scott
Gottlieb, the head of the US Food and Drug Administration, tweeted on
Wednesday that “certain uses of science should be judged intolerable,
and cause scientists to be cast out. The use of CRISPR to edit human
embryos or germ line cells should fall into that bucket.” In an
interview with BioCentury, Gottlieb further specified that the
restriction should apply if the cells are “for reproduction.”
Right now, Gottlieb can’t cast out people, like Neuhausser, who are
doing basic research. Sperm, like dot-size IVF embryos, don’t have much
in the way of legal rights in the US. But he can frighten scientists,
make their work harder, and drive the work overseas.
Already, Neuhausser works under many restrictions. Public funding
for embryo research from the National Institutes of Health is forbidden.
In Massachusetts, unlike some other states, it is also illegal to make
an embryo just to study it.
That means if the time comes to test the CRISPR sperm to make an
embryo, the research will have to move away from Boston. Neuhausser was
in China last month exploring the possibilities of making research
embryos there. So far, those plans haven’t come together.
For now, ApoE is a toy example, one to try in the lab to test the
technology and its potential. It’s not certain yet whether changing this
gene would alter a child’s risk of Alzheimer’s later in life. Despite
very strong links to the brain disease, there is no rock-solid proof
that ApoE is a cause. “It’s one of the main risk factors for
Alzheimer’s, although no one has shown causality,” says Neuhausser. “The
point is to show the principle.”
But slashing a newborn’s lifelong risk of Alzheimer’s would be a
huge deal. So would the ability to fix mutations that cause Lou Gehrig’s
disease, another illness the team is looking into. Neuhausser expects
it will eventually be routine to improve the DNA of sperm or embryos—and
the people they turn into—in fundamental ways.
“The big question is when is it ready for prime time,” says Alan
Penzias, the endocrinologist who oversees research at Boston IVF. “I
would say we are a few years away. But that sounds pretty close to me,
to tell you the truth. It is something that we would be happy to do, and
we would like to do in a responsible way.”
Saving the species
With Boston IVF, Neuhausser has been carrying out a survey of
doctors and hundreds of patients about what they think. “For treating or
preventing disease, pretty much everyone agrees,” he says—that is, they
are for it.
People do draw the line at things like increasing height or
changing eye color, with only a tiny percentage thinking it’s a good
idea. Neuhausser admits someone might do that too, eventually. “Like any
technology, there will be misuses,” he says. “But it’s important that
we return to a rational approach, recognizing that this has huge
potential and huge risks. The problem is that when people get scared,
things get shut down. That is why people are nervous about He—he’s
hurting everyone else.”
To anyone who wants to end this line of research, the Harvard
doctors have one last ace to play. They say germ-line editing might be
an important technology to have for civilization’s sake.
What if a new killer virus arises and sweeps the world? Maybe there
will be no vaccine but some people will be able to resist it thanks to
their genes, as some fared better with the Black Death in medieval
times. Wouldn’t we want to then give the genetic antidote to all members
of the next generation?
“This is a technology that could save the species, potentially,”
says Neuhausser. In his speech in Hong Kong, Daley also referenced the
potential defense against future disease.
“We as a species need to maintain the flexibility to face future threats, to take control of our heredity,” he said.
Doc. RNDr. Josef Reischig, CSc. | Wikimedia Commons
At each time step, the process is in some state , and the decision maker may choose any action that is available in state . The process responds at the next time step by randomly moving into a new state , and giving the decision maker a corresponding reward .
The probability that the process moves into its new state is influenced by the chosen action. Specifically, it is given by the state transition function . Thus, the next state depends on the current state and the decision maker's action . But given and ,
it is conditionally independent of all previous states and actions; in
other words, the state transitions of an MDP satisfies the Markov property.
Markov decision processes are an extension of Markov chains;
the difference is the addition of actions (allowing choice) and rewards
(giving motivation). Conversely, if only one action exists for each
state (e.g. "wait") and all rewards are the same (e.g. "zero"), a Markov
decision process reduces to a Markov chain.
Definition
Example of a simple MDP with three states (green circles) and two actions (orange circles), with two rewards (orange arrows).
is a finite set of actions (alternatively, is the finite set of actions available from state );
is the probability that action in state at time will lead to state at time ;
is the immediate reward (or expected immediate reward) received after transitioning from state to state , due to action .
(Note: The theory of Markov decision processes does not state that or are finite, but the basic algorithms below assume that they are finite.)
Problem
The core problem of MDPs is to find a "policy" for the decision maker: a function that specifies the action that the decision maker will choose when in state .
Once a Markov decision process is combined with a policy in this way,
this fixes the action for each state and the resulting combination
behaves like a Markov chain (since the action chosen in state is completely determined by and reduces to , a Markov transition matrix).
The goal is to choose a policy
that will maximize some cumulative function of the random rewards,
typically the expected discounted sum over a potentially infinite
horizon:
(where we choose , i.e. actions given by the policy),
where is the discount factor and satisfies . (For example, when the discount rate is r.) is typically close to 1.
Because of the Markov property, the optimal policy for this particular problem can indeed be written as a function of only, as assumed above.
Algorithms
The
solution for an MDP is a policy which describes the best action for
each state in the MDP, known as the optimal policy. This optimal policy
can be found through a variety of methods, like dynamic programming.
Some dynamic programming solutions require knowledge of the state transition function and the reward function . Others can solve for the optimal policy of an MDP using experimentation alone.
Consider the case in which there is a given the state transition function and reward function for an MDP, and we seek the optimal policy that maximizes the expected discounted reward.
The standard family of algorithms to calculate this optimal policy requires storage for two arrays indexed by state: value, which contains real values, and policy which contains actions. At the end of the algorithm, will contain the solution and will contain the discounted sum of the rewards to be earned (on average) by following that solution from state .
The algorithm has two kinds of steps, a value update and a policy
update, which are repeated in some order for all the states until no
further changes take place. Both recursively update
a new estimation of the optimal policy and state value using an older
estimation of those values.
Their order depends on the variant of the algorithm; one can also do
them for all states at once or state by state, and more often to some
states than others. As long as no state is permanently excluded from
either of the steps, the algorithm will eventually arrive at the correct
solution.
Notable variants
Value iteration
In value iteration (Bellman 1957), which is also called backward induction,
the function is not used; instead, the value of is calculated within whenever it is needed. Substituting the calculation of into the calculation of gives the combined step:
where is the iteration number. Value iteration starts at and as a guess of the value function. It then iterates, repeatedly computing for all states , until converges with the left-hand side equal to the right-hand side (which is the "Bellman equation" for this problem). Lloyd Shapley's 1953 paper on stochastic games included as a special case the value iteration method for MDPs, but this was recognized only later on.
Policy iteration
In policy iteration (Howard 1960),
step one is performed once, and then step two is repeated until it
converges. Then step one is again performed once and so on.
Instead of repeating step two to convergence, it may be
formulated and solved as a set of linear equations. These equations are
merely obtained by making in the step two equation. Thus, repeating step two to convergence can be interpreted as solving the linear equations by Relaxation (iterative method).
This variant has the advantage that there is a definite stopping condition: when the array does not change in the course of applying step 1 to all states, the algorithm is completed.
Policy iteration is usually slower than value iteration for a large number of possible states.
Modified policy iteration
In modified policy iteration (van Nunen 1976; Puterman & Shin 1978), step one is performed once, and then step two is repeated several times. Then step one is again performed once and so on.
Prioritized sweeping
In
this variant, the steps are preferentially applied to states which are
in some way important – whether based on the algorithm (there were large
changes in or
around those states recently) or based on use (those states are near
the starting state, or otherwise of interest to the person or program
using the algorithm).
Extensions and generalizations
A Markov decision process is a stochastic game with only one player.
Partial observability
The solution above assumes that the state is known when action is to be taken; otherwise
cannot be calculated. When this assumption is not true, the problem is
called a partially observable Markov decision process or POMDP.
A major advance in this area was provided by Burnetas and
Katehakis in "Optimal adaptive policies for Markov decision processes".
In this work, a class of adaptive policies that possess uniformly
maximum convergence rate properties for the total expected finite
horizon reward were constructed under the assumptions of finite
state-action spaces and irreducibility of the transition law. These
policies prescribe that the choice of actions, at each state and time
period, should be based on indices that are inflations of the right-hand
side of the estimated average reward optimality equations.
Reinforcement learning
If the probabilities or rewards are unknown, the problem is one of reinforcement learning.
For this purpose it is useful to define a further function, which corresponds to taking the action and then continuing optimally (or according to whatever policy one currently has):
While this function is also unknown, experience during learning is based on pairs (together with the outcome ; that is, "I was in state and I tried doing and happened"). Thus, one has an array and uses experience to update it directly. This is known as Q-learning.
Reinforcement learning can solve Markov decision processes
without explicit specification of the transition probabilities; the
values of the transition probabilities are needed in value and policy
iteration. In reinforcement learning, instead of explicit specification
of the transition probabilities, the transition probabilities are
accessed through a simulator that is typically restarted many times from
a uniformly random initial state. Reinforcement learning can also be
combined with function approximation to address problems with a very
large number of states.
Learning automata
Another application of MDP process in machine learning
theory is called learning automata. This is also one type of
reinforcement learning if the environment is stochastic. The first
detail learning automata paper is surveyed by Narendra and Thathachar (1974), which were originally described explicitly as finite state automata.
Similar to reinforcement learning, learning automata algorithm also has
the advantage of solving the problem when probability or rewards are
unknown. The difference between learning automata and Q-learning is that
they omit the memory of Q-values, but update the action probability
directly to find the learning result. Learning automata is a learning
scheme with a rigorous proof of convergence.
In learning automata theory, a stochastic automaton consists of:
a set x of possible inputs,
a set Φ = { Φ1, ..., Φs } of possible internal states,
a set α = { α1, ..., αr } of possible outputs, or actions, with r≤s,
an initial state probability vector p(0) = ≪ p1(0), ..., ps(0) ≫,
a computable functionA which after each time step t generates p(t+1) from p(t), the current input, and the current state, and
a function G: Φ → α which generates the output at each time step.
The states of such an automaton correspond to the states of a "discrete-state discrete-parameter Markov process". At each time step t=0,1,2,3,..., the automaton reads an input from its environment, updates P(t) to P(t+1) by A, randomly chooses a successor state according to the probabilities P(t+1)
and outputs the corresponding action. The automaton's environment, in
turn, reads the action and sends the next input to the automaton.
Category theoretic interpretation
Other than the rewards, a Markov decision process can be understood in terms of Category theory. Namely, let denote the free monoid with generating set A. Let Dist denote the Kleisli category of the Giry monad. Then a functor encodes both the set S of states and the probability function P.
In this way, Markov decision processes could be generalized from
monoids (categories with one object) to arbitrary categories. One can
call the result a context-dependent Markov decision process, because moving from one object to another in changes the set of available actions and the set of possible states.
Fuzzy Markov decision processes (FMDPs)
In
the MDPs, an optimal policy is a policy which maximizes the
probability-weighted summation of future rewards. Therefore, an optimal
policy consists of several actions which belong to a finite set of
actions. In fuzzy Markov decision processes (FMDPs), first, the value
function is computed as regular MDPs (i.e., with a finite set of
actions); then, the policy is extracted by a fuzzy inference system. In
other words, the value function is utilized as an input for the fuzzy
inference system, and the policy is the output of the fuzzy inference
system.
Continuous-time Markov decision process
In discrete-time Markov Decision Processes, decisions are made at discrete time intervals. However, for continuous-time Markov decision processes,
decisions can be made at any time the decision maker chooses. In
comparison to discrete-time Markov decision processes, continuous-time
Markov decision processes can better model the decision making process
for a system that has continuous dynamics, i.e., the system dynamics is defined by partial differential equations (PDEs).
Definition
In order to discuss the continuous-time Markov decision process, we introduce two sets of notations:
If the state space and action space are finite,
: State space;
: Action space;
: , transition rate function;
: , a reward function.
If the state space and action space are continuous,
: state space;
: space of possible control;
: , a transition rate function;
: , a reward rate function such that , where is the reward function we discussed in previous case.
Problem
Like the discrete-time Markov decision processes, in continuous-time Markov decision processes we want to find the optimal policy or control which could give us the optimal expected integrated reward:
Where
Linear programming formulation
If
the state space and action space are finite, we could use linear
programming to find the optimal policy, which was one of the earliest
approaches applied. Here we only consider the ergodic model, which means
our continuous-time MDP becomes an ergodic continuous-time Markov chain under a stationary policy.
Under this assumption, although the decision maker can make a decision
at any time at the current state, he could not benefit more by taking
more than one action. It is better for him to take an action only at the
time when system is transitioning from the current state to another
state. Under some conditions, if our optimal value function is independent of state , we will have the following inequality:
If there exists a function , then will be the smallest satisfying the above equation. In order to find , we could use the following linear programming model:
Primal linear program(P-LP);
Dual linear program(D-LP);
is a feasible solution to the D-LP if is
nonnative and satisfied the constraints in the D-LP problem. A
feasible solution to the D-LP is said to be an optimal
solution if:
for all feasible solution to the D-LP.
Once we have found the optimal solution , we can use it to establish the optimal policies.
Hamilton–Jacobi–Bellman equation
In continuous-time MDP, if the state space and action space are continuous, the optimal criterion could be found by solving Hamilton–Jacobi–Bellman (HJB) partial differential equation.
In order to discuss the HJB equation, we need to reformulate
our problem
is the terminal reward function, is the
system state vector, is the system control vector we try to
find. shows how the state vector changes over time.
The Hamilton–Jacobi–Bellman equation is as follows:
We could solve the equation to find the optimal control , which could give us the optimal value
The
terminology and notation for MDPs are not entirely settled. There are
two main streams — one focuses on maximization problems from contexts
like economics, using the terms action, reward, value, and calling the
discount factor or ,
while the other focuses on minimization problems from engineering and
navigation, using the terms control, cost, cost-to-go, and calling the
discount factor . In addition, the notation for the transition probability varies.
in this article
alternative
comment
action
control
reward
cost
is the negative of
value
cost-to-go
is the negative of
policy
policy
discounting factor
discounting factor
transition probability
transition probability
In addition, transition probability is sometimes written, or, rarely,
Constrained Markov decision processes
Constrained
Markov decision processes (CMDPs) are extensions to Markov decision
process (MDPs). There are three fundamental differences between MDPs and
CMDPs:
There are multiple costs incurred after applying an action instead of one.



























































![{\displaystyle \max \quad \mathbb {E} _{u}\left[\left.\int _{0}^{\infty }\gamma ^{t}r(x(t),u(t)))dt\;\right|x_{0}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3a1a607327986615b6f81c5b08e371182798c55a)











![{\displaystyle {\begin{aligned}V(x(0),0)={}&\max _{u}\int _{0}^{T}r(x(t),u(t))\,dt+D[x(T)]\\{\text{s.t.}}\quad &{\frac {dx(t)}{dt}}=f[t,x(t),u(t)]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3b798dc9345b260fe104fc55b5cdb475d1f9e006)













