
When Machines Know: The Evolution of Knowledge and Artificial Intelligence
Joseph Schumpeter described shifts like this as a kind of “creative destruction” unleashed by innovation - cycles of economic destruction and creation, catalyzed by waves of new technology. We are now about to enter a new phase of creative destruction as machines begin taking over the work of transforming information into knowledge.
A Knowledge Hierarchy
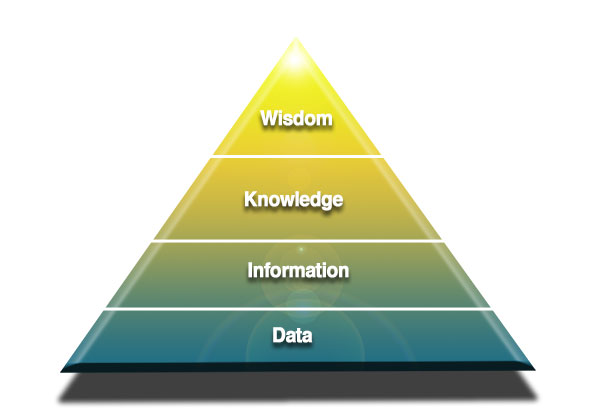
If you’re ever bored and looking for some fun, try telling a knowledge management expert that you’ve figured out the exact meaning of this diagram to the right.
It’s a “knowledge hierarchy” or “DIKW Pyramid” (DIKW = Data, Information, Knowledge and Wisdom) and lots of people have lots of opinions about what it means.
So, here’s my take on the D, I, K and W:
- Data: Internal or environmental signals
- Information: Data, filtered by implicit or explicit intention
- Knowledge: Information, transformed into meaning
- Wisdom: Knowledge that has been experienced
Embedded Knowledge

Through most of our history, we’ve embedded our knowledge in our minds and bodies through various types of human memory. The invention of symbols and writing eventually gave us a way to embed that knowledge into something else. In a way, our history is a history of that ‘something else.’
Knowledge management experts like to divide knowledge into two categories: tacit knowledge and explicit knowledge. Tacit knowledge is experience-based knowledge – things we know, but don’t really know how we know – like riding a bike, speaking a language or playing the guitar. Explicit knowledge is knowledge that is articulated. We embed explicit knowledge in written rules, procedures – and increasingly, in software. We embed tacit knowledge in memory and explicit knowledge in information systems.
Though the relationship between these two forms of knowledge is complex, the story of human civilization is an accelerating conversion of implicit knowledge into explicit knowledge.
And we’re just getting started.
Artificial Intelligence Information Filtering
When it comes to developing knowledge, the first step is determining which signals have value and which are just noise. If we can offload that pattern-recognizing work to machines, we take a big step towards automating knowledge creation.Until recently, our information systems for doing that kind of filtering have been “deterministic,” which is to say, you take an input, apply pre-determined rules coded by a software developer, and it spits out a pre-determined output. The system never knows more than the coders who coded it.
That’s now changing. “Deep Learning” is a branch of artificial intelligence that tackles complex pattern recognition problems by breaking them into layers of simpler pattern recognition problems. What’s striking about recent Deep Learning breakthroughs is that they’re able to learn on their own. Google recently used Deep Learning algorithms to achieve an 82% accuracy in detecting faces among a set of some 37,000 images. That may not sound impressive until you realize that these techniques required no training of the algorithm in advance. By simply exposing the Deep Learning software to enough data, an efficient face-recognizing ‘neuron’ emerged without humans having to code it. Google ran similar tests for recognizing human bodies and even cats on YouTube.

With Deep Learning, software developers don’t have to know the answers before they code. The software trains itself. It learns. And what it’s learning is how to automatically turn data into information with minimal human intervention.
I like digging beneath the surface of technology, and from that place, you could say that the digital neurons of today’s Deep Learning software are roughly analogous to the sensory neurons that emerged in biology hundreds of millions of years ago. I think there’s no coincidence that today’s sensor technologies are creating an explosion of precisely the kind of data that Deep Learning is so well-suited to process, or that the first real practical applications of Deep Learning are in image processing and speech recognition – digital extensions of biology’s eyes and ears.
We are now embedding our knowledge into a new digital container, and these automated information processing techniques are a vital step in that direction.
Automating Meaning Extraction
The algorithm didn’t know the word “cat” — Ng had to supply that — but over time, it learned to identify the furry creatures we know as cats, all on its own. This approach is inspired by how scientists believe that humans learn. As babies, we watch our environments and start to understand the structure of objects we encounter, but until a parent tells us what it is, we can’t put a name to it. – Wired

Google’s algorithm could find cats, but couldn’t connect the ‘cat pattern’ to the word “cat.”
Knowledge is only part pattern recognition. We can learn to correctly spot a smoke signal in the distance, but knowing what it means is what makes that pattern useful.
When it comes to transforming information into knowledge, meaning-making is a critical function – and it just so happens that humans are really good at it.
One way of thinking about meaning-making is connecting ideas to one another. I think of a camera and it kicks off a cascade of related ideas from shutter speed, to Android phones, and the Kodak Corporation. The technology for making these associative connections has been around for a while. In 2001, web inventor, Tim Berners-Lee painted a compelling vision for a new web connected through meaning, which he called the “semantic web.”
One of the legitimate criticisms of the semantic web is that implementing it requires too much expertise and work on the part of website publishers. Better, the thinking goes, to push this work off to machines.
There are many approaches to automating meaning extraction on the web. The most intriguing to me, because of its audacious scale and the fact that Google is behind it, is the Knowledge Graph. Google originally seeded its Knowledge Graph with data from a number of sources, including Freebase, which it acquired in 2010, and which used an interesting combination of automation and crowd-sourced human editing to build a huge, and highly structured, database of knowledge. As of this writing, Freebase includes some 45 million topics.

Over time, Google has expanded the automation techniques used by Freebase in some interesting ways. It’s been exceptionally smart in using people’s interactions with Search and other services to augment the Knowledge Graph. For example, when I search for “Thomas Paine” just after searching for “Thomas Jefferson,” and lots of others do the same, Google can infer a relationship between the two men, which is then added to the Knowledge Graph. They also surface that useful information to users as “other people searched for” listings on the right-hand side of the search results.
Now Google is taking this automation to a new level by automating the extraction of meaning, much the way their search bots crawl and extract data from websites today by combining that information with prior knowledge stored in the Knowledge Graph. One of Google’s internal projects for doing this is loosely termed the “Knowledge Vault” (detailed PDF research paper), and I believe it, or something like it, has the potential to be quite important.
Google is now using these techniques to embed human meaning into a growing web of words and the meaning behind those words. It’s important to bear in mind that the seeds of all of this knowledge (the entries in Freebase and the websites that Google crawls) were all human in origin. Google is just using some really smart techniques for extracting and processing this information in order to synthesize meaning out of it.
From the bigger perspective, you could say that Google is using these techniques to extract tacit knowledge from us and embed it as explicit knowledge into machines. Yes, machines can find pictures of cats without our help, but when it comes to knowing that these cat patterns are actually “cats” and knowing what cats mean, well, they still need some help from humans.
At least for now.
Creating a New Container: The Fusion of Knowledge and Artificial Intelligence

We are making good progress in automating filters to transform data into information and in automating the way we attach meaning to that information. These are important steps to automating the transformation of humanity’s tacit knowledge into explicit knowledge stored in machines. Soon we will be doing it on a staggering scale.
There are many questions with regard to where this is all headed. There’s little question that these new tools will bring economic ‘destruction’ for many lower-end knowledge workers. Still, where there is destruction, there is also creation. Just look at what IBM is doing with Watson Discovery Advisor, a service designed to help humans use the power of machine learning to uncover creative insights in science, healthcare, law and even gourmet cooking:
I believe we are on a learning curve that is of our own creation but that is not exactly ours. What we are seeing today is the earth’s most intelligent species extracting knowledge from the biology in which it is currently embedded and moving it into something else.
If my take on the knowledge pyramid is correct, and knowledge does have to be experienced in order to become wisdom, then let us hope that whatever arises next will be more than just data, information or knowledge. Let us hope that it will be capable of a conscious experience that leads to true wisdom.


