The first automated DNA sequencer, invented by Lloyd M. Smith, was introduced by Applied Biosystems in 1987. It used the Sanger sequencing method, a technology which formed the basis of the “first generation” of DNA sequencers and enabled the completion of the human genome project in 2001. This first generation of DNA sequencers are essentially automated electrophoresis systems that detect the migration of labelled DNA fragments. Therefore, these sequencers can also be used in the genotyping of genetic markers where only the length of a DNA fragment(s) needs to be determined (e.g. microsatellites, AFLPs).
The Human Genome Project spurred the development of cheaper, high throughput and more accurate platforms known as Next Generation Sequencers (NGS) to sequence the human genome. These include the 454, SOLiD and Illumina
DNA sequencing platforms. Next generation sequencing machines have
increased the rate of DNA sequencing substantially, as compared with the
previous Sanger methods. DNA samples can be prepared automatically in
as little as 90 mins, while a human genome can be sequenced at 15 times coverage in a matter of days.
More recent, third-generation DNA sequencers such as SMRT and Oxford Nanopore measure the addition of nucleotides to a single DNA molecule in real time.
Because of limitations in DNA sequencer technology these reads are short compared to the length of a genome therefore the reads must be assembled into longer contigs. The data may also contain errors, caused by limitations in the DNA sequencing technique or by errors during PCR amplification.
DNA sequencer manufacturers use a number of different methods to detect
which DNA bases are present. The specific protocols applied in
different sequencing platforms have an impact in the final data that is
generated. Therefore, comparing data quality and cost across different
technologies can be a daunting task. Each manufacturer provides their
own ways to inform sequencing errors and scores. However, errors and
scores between different platforms cannot always be compared directly.
Since these systems rely on different DNA sequencing approaches,
choosing the best DNA sequencer and method will typically depend on the
experiment objectives and available budget.
History
The first DNA sequencing methods were developed by Gilbert (1973) and Sanger (1975).
Gilbert introduced a sequencing method based on chemical modification
of DNA followed by cleavage at specific bases whereas Sanger’s technique
is based on dideoxynucleotide
chain termination. The Sanger method became popular due to its
increased efficiency and low radioactivity. The first automated DNA
sequencer was the AB370A, introduced in 1986 by Applied Biosystems.
The AB370A was able to sequence 96 samples simultaneously, 500
kilobases per day, and reaching read lengths up to 600 bases. This was
the beginning of the “first generation” of DNA sequencers,
which implemented Sanger sequencing, fluorescent dideoxy nucleotides
and polyacrylamide gel sandwiched between glass plates - slab gels. The
next major advance was the release in 1995 of the AB310 which utilized a
linear polymer in a capillary in place of the slab gel for DNA strand
separation by electrophoresis. These techniques formed the base for the
completion of the human genome project in 2001.
The human genome project spurred the development of cheaper, high
throughput and more accurate platforms known as Next Generation
Sequencers (NGS). In 2005, 454 Life Sciences
released the 454 sequencer, followed by Solexa Genome Analyzer and
SOLiD (Supported Oligo Ligation Detection) by Agencourt in 2006. Applied
Biosystems acquired Agencourt in 2006, and in 2007, Roche bought 454
Life Sciences, while Illumina purchased Solexa. Ion Torrent entered the
market in 2010 and was acquired by Life Technologies (now Thermo Fisher
Scientific). These are still the most common NGS systems due to their
competitive cost, accuracy, and performance.
More recently, a third generation of DNA sequencers was
introduced. The sequencing methods applied by these sequencers do not
require DNA amplification (polymerase chain reaction – PCR), which
speeds up the sample preparation before sequencing and reduces errors.
In addition, sequencing data is collected from the reactions caused by
the addition of nucleotides in the complementary strand in real time.
Two companies introduced different approaches in their third-generation
sequencers. Pacific Biosciences sequencers utilize a method called
Single-molecule real-time (SMRT), where sequencing data is produced by
light (captured by a camera) emitted when a nucleotide is added to the
complementary strand by enzymes containing fluorescent dyes. Oxford
Nanopore Technologies is another company developing third-generation
sequencers using electronic systems based on nanopore sensing
technologies.
Manufacturers of DNA sequencers
DNA sequencers have been developed, manufactured, and sold by the following companies, among others.
Roche
The 454 DNA sequencer was the first next-generation sequencer to become commercially successful.
It was developed by 454 Life Sciences and purchased by Roche in 2007.
454 utilizes the detection of pyrophosphate released by the DNA
polymerase reaction when adding a nucleotide to the template strain.
Roche currently manufactures two systems based on their pyrosequencing technology: the GS FLX+ and the GS Junior System.
The GS FLX+ System promises read lengths of approximately 1000 base
pairs while the GS Junior System promises 400 base pair reads.
A predecessor to GS FLX+, the 454 GS FLX Titanium system was released
in 2008, achieving an output of 0.7G of data per run, with 99.9%
accuracy after quality filter, and a read length of up to 700bp. In
2009, Roche launched the GS Junior, a bench top version of the 454
sequencer with read length up to 400bp, and simplified library
preparation and data processing.
One of the advantages of 454 systems is their running speed,
Manpower can be reduced with automation of library preparation and
semi-automation of emulsion PCR. A disadvantage of the 454 system is
that it is prone to errors when estimating the number of bases in a long
string of identical nucleotides. This is referred to as a homopolymer
error and occurs when there are 6 or more identical bases in row. Another disadvantage is that the price of reagents is relatively more expensive compared with other next-generation sequencers.
In 2013 Roche announced that they would be shutting down
development of 454 technology and phasing out 454 machines completely in
2016.
Roche produces a number of software tools which are optimised for the analysis of 454 sequencing data. GS Run Processor
converts raw images generated by a sequencing run into intensity
values. The process consists of two main steps: image processing and
signal processing. The software also applies normalization, signal
correction, base-calling and quality scores for individual reads. The
software outputs data in Standard Flowgram Format (or SFF) files to be
used in data analysis applications (GS De Novo Assembler, GS Reference
Mapper or GS Amplicon Variant Analyzer). GS De Novo Assembler is a tool
for de novo assembly of whole-genomes up to 3GB in size from
shotgun reads alone or combined with paired end data generated by 454
sequencers. It also supports de novo assembly of transcripts (including
analysis), and also isoform variant detection.
GS Reference Mapper maps short reads to a reference genome, generating a
consensus sequence. The software is able to generate output files for
assessment, indicating insertions, deletions and SNPs. Can handle large
and complex genomes of any size.
Finally, the GS Amplicon Variant Analyzer aligns reads from amplicon
samples against a reference, identifying variants (linked or not) and
their frequencies. It can also be used to detect unknown and
low-frequency variants. It includes graphical tools for analysis of
alignments.
Illumina
Illumina Genome Analyzer II sequencing machine
Illumina produces a number of next-generation sequencing machines using technology acquired from Manteia Predictive Medicine and developed by Solexa.
Illumina makes a number of next generation sequencing machines using
this technology including the HiSeq, Genome Analyzer IIx, MiSeq and the
HiScanSQ, which can also process microarrays.
The technology leading to these DNA sequencers was first released by Solexa in 2006 as the Genome Analyzer.
Illumina purchased Solexa in 2007. The Genome Analyzer uses a
sequencing by synthesis method. The first model produced 1G per run.
During the year 2009 the output was increased from 20G per run in August
to 50G per run in December. In 2010 Illumina released the HiSeq 2000
with an output of 200 and then 600G per run which would take 8 days. At
its release the HiSeq 2000 provided one of the cheapest sequencing
platforms at $0.02 per million bases as costed by the Beijing Genomics Institute.
In 2011 Illumina released a benchtop sequencer called the MiSeq.
At its release the MiSeq could generate 1.5G per run with paired end
150bp reads. A sequencing run can be performed in 10 hours when using
automated DNA sample preparation.
The Illumina HiSeq uses two software tools to calculate the
number and position of DNA clusters to assess the sequencing quality:
the HiSeq control system and the real-time analyzer. These methods help
to assess if nearby clusters are interfering with each other.
Life Technologies
Life Technologies (now Thermo Fisher Scientific) produces DNA sequencers under the Applied Biosystems and Ion Torrent brands. Applied Biosystems makes the SOLiD next-generation sequencing platform, and Sanger-based DNA sequencers such as the 3500 Genetic Analyzer.
Under the Ion Torrent brand, Applied Biosystems produces four
next-generation sequencers: the Ion PGM System, Ion Proton System, Ion
S5 and Ion S5xl systems.
The company is also believed to be developing their new capillary DNA
sequencer called SeqStudio that will be released early 2018.
SOLiD systems was acquired by Applied Biosystems in 2006. SOLiD applies sequencing by ligation and dual base encoding.
The first SOLiD system was launched in 2007, generating reading lengths
of 35bp and 3G data per run. After five upgrades, the 5500xl sequencing
system was released in 2010, considerably increasing read length to
85bp, improving accuracy up to 99.99% and producing 30G per 7-day run.
The limited read length of the SOLiD has remained a significant shortcoming
and has to some extent limited its use to experiments where read length
is less vital such as resequencing and transcriptome analysis and more
recently ChIP-Seq and methylation experiments.
The DNA sample preparation time for SOLiD systems has become much
quicker with the automation of sequencing library preparations such as
the Tecan system.
The colour space data produced by the SOLiD platform can be
decoded into DNA bases for further analysis, however software that
considers the original colour space information can give more accurate
results. Life Technologies has released BioScope,
a data analysis package for resequencing, ChiP-Seq and transcriptome
analysis. It uses the MaxMapper algorithm to map the colour space reads.
Beckman Coulter
Beckman Coulter (now Danaher)
has previously manufactured chain termination and capillary
electrophoresis-based DNA sequencers under the model name CEQ, including
the CEQ 8000. The company now produces the GeXP Genetic Analysis
System, which uses dye terminator sequencing. This method uses a thermocycler in much the same way as PCR to denature, anneal, and extend DNA fragments, amplifying the sequenced fragments.
Pacific Biosciences
Pacific Biosciences produces the PacBio RS and Sequel sequencing systems using a single molecule real time sequencing, or SMRT, method.
This system can produce read lengths of multiple thousands of base
pairs. Higher raw read errors are corrected using either circular
consensus - where the same strand is read over and over again - or using
optimized assembly strategies. Scientists have reported 99.9999% accuracy with these strategies. The Sequel system was launched in 2015 with an increased capacity and a lower price.
Oxford Nanopore MinION sequencer (lower right) was used in the first-ever DNA sequencing in space in August 2016 by astronaut Kathleen Rubins.
Oxford Nanopore
Oxford Nanopore Technologies has begun shipping early versions of its nanopore sequencing MinION sequencer to selected labs. The device is four inches long and gets power from a USB port. MinION decodes DNA directly as the molecule is drawn at the rate of 450 bases/second through a nanopore
suspended in a membrane. Changes in electric current indicate which
base is present. It is 60 to 85 percent accurate, compared with 99.9
percent in conventional machines. Even inaccurate results may prove
useful because it produces long read lengths. GridION is a slightly
larger sequencer that processes up to five MinION flow cells at once.
PromethION is another (unreleased) product that will use as many as
100,000 pores in parallel, more suitable for high volume sequencing.
The 1000 Genomes Project (abbreviated as 1KGP), launched in January 2008, was an international research effort to establish by far the most detailed catalogue of human genetic variation. Scientists planned to sequence the genomes
of at least one thousand anonymous participants from a number of
different ethnic groups within the following three years, using newly developed technologies
which were faster and less expensive. In 2010, the project finished its
pilot phase, which was described in detail in a publication in the
journal Nature. In 2012, the sequencing of 1092 genomes was announced in a Nature publication. In 2015, two papers in Nature reported results and the completion of the project and opportunities for future research.
Many rare variations, restricted to closely related groups, were
identified, and eight structural-variation classes were analyzed.
The project unites multidisciplinary research teams from institutes around the world, including China, Italy, Japan, Kenya, Nigeria, Peru, the United Kingdom, and the United States. Each will contribute to the enormous sequence dataset and to a refined human genome map, which will be freely accessible through public databases to the scientific community and the general public alike.
By providing an overview of all human genetic variation, the
consortium will generate a valuable tool for all fields of biological
science, especially in the disciplines of genetics, medicine, pharmacology, biochemistry, and bioinformatics.
Changes in the number and order of genes (A-D) create genetic diversity within and between populations.
The random sampling of gametes during sexual reproduction leads to genetic drift
— a random fluctuation in the population frequency of a trait — in
subsequent generations and would result in the loss of all variation in
the absence of external influence. It is postulated that the rate of
genetic drift is inversely proportional to population size, and that it
may be accelerated in specific situations such as bottlenecks, where the population size is reduced for a certain period of time, and by the founder effect (individuals in a population tracing back to a small number of founding individuals).
Anzai et al. demonstrated that indels account for 90.4% of all observed variations in the sequence of the major histocompatibility locus (MHC) between humans and chimpanzees. After taking multiple indels into consideration, the high degree of genomic similarity between the two species (98.6% nucleotide sequence identity) drops to only 86.7%. For example, a large deletion of 95 kilobases (kb) between the loci of the human MICA and MICBgenes, results in a single hybrid chimpanzee MIC gene, linking this region to a species-specific handling of several retroviral infections and the resultant susceptibility to various autoimmune diseases. The authors conclude that instead of more subtle SNPs, indels were the driving mechanism in primate speciation.
Besides mutations, SNPs and other structural variants such as copy-number variants (CNVs) are contributing to the genetic diversity in human populations. Using microarrays,
almost 1,500 copy number variable regions, covering around 12% of the
genome and containing hundreds of genes, disease loci, functional
elements and segmental duplications, have been identified in the HapMap
sample collection. Although the specific function of CNVs remains
elusive, the fact that CNVs span more nucleotide content per genome than
SNPs emphasizes the importance of CNVs in genetic diversity and
evolution.
Investigating human genomic variations holds great potential for
identifying genes that might underlie differences in disease resistance
(e.g. MHC region) or drug metabolism.
Natural selection
Natural selection in the evolution of a trait can be divided into three classes. Directional or positive selection refers to a situation where a certain allele has a greater fitness than other alleles, consequently increasing its population frequency (e.g. antibiotic resistance of bacteria). In contrast, stabilizing or negative selection
(also known as purifying selection) lowers the frequency or even
removes alleles from a population due to disadvantages associated with
it with respect to other alleles. Finally, a number of forms of balancing selection exist; those increase genetic variation within a species by being overdominant (heterozygous individuals are fitter than homozygous individuals, e.g. G6PD, a gene that is involved in both Hemolytic anaemia and malaria resistance) or can vary spatially within a species that inhabits different niches, thus favouring different alleles.
Some genomic differences may not affect fitness. Neutral variation,
previously thought to be “junk” DNA, is unaffected by natural selection
resulting in higher genetic variation at such sites when compared to
sites where variation does influence fitness.
It is not fully clear how natural selection has shaped population
differences; however, genetic candidate regions under selection have
been identified recently. Patterns of DNA polymorphisms
can be used to reliably detect signatures of selection and may help to
identify genes that might underlie variation in disease resistance or
drug metabolism. Barreiro et al. found evidence that negative selection has reduced population differentiation at the amino acid–altering
level (particularly in disease-related genes), whereas, positive
selection has ensured regional adaptation of human populations by
increasing population differentiation in gene regions (mainly nonsynonymous and 5'-untranslated region variants).
It is thought that most complex and Mendelian diseases
(except diseases with late onset, assuming that older individuals no
longer contribute to the fitness of their offspring) will have an effect
on survival and/or reproduction, thus, genetic factors underlying those
diseases should be influenced by natural selection. Although, diseases
that have late onset today could have been childhood diseases in the
past as genes delaying disease progression could have undergone
selection. Gaucher disease (mutations in the GBA gene), Crohn's disease (mutation of NOD2) and familial hypertrophic cardiomyopathy (mutations in MYH7, TNNT2, TPM1 and MYBPC3)
are all examples of negative selection. These disease mutations are
primarily recessive and segregate as expected at a low frequency,
supporting the hypothesized negative selection. There is evidence that
the genetic-basis of Type 1 Diabetes may have undergone positive selection.
Few cases have been reported, where disease-causing mutations appear at
the high frequencies supported by balanced selection. The most
prominent example is mutations of the G6PD locus where, if homozygous G6PD enzyme deficiency and consequently Hemolytic anaemia results, but in the heterozygous state are partially protective against malaria.
Other possible explanations for segregation of disease alleles at
moderate or high frequencies include genetic drift and recent
alterations towards positive selection due to environmental changes such
as diet or genetic hitch-hiking.
Genome-wide comparative analyses
of different human populations, as well as between species (e.g. human
versus chimpanzee) are helping us to understand the relationship between
diseases and selection and provide evidence of mutations in constrained
genes being disproportionally associated with heritable diseasephenotypes.
Genes implicated in complex disorders tend to be under less negative
selection than Mendelian disease genes or non-disease genes.
Project description
Goals
There
are two kinds of genetic variants related to disease. The first are
rare genetic variants that have a severe effect predominantly on simple
traits (e.g. Cystic fibrosis, Huntington disease). The second, more common, genetic variants have a mild effect and are thought to be implicated in complex traits (e.g. Cognition, Diabetes, Heart Disease).
Between these two types of genetic variants lies a significant gap of
knowledge, which the 1000 Genomes Project is designed to address.
The primary goal of this project is to create a complete and detailed catalogue of human genetic variations, which in turn can be used for association studies
relating genetic variation to disease. By doing so the consortium aims
to discover >95 % of the variants (e.g. SNPs, CNVs, indels) with minor allele frequencies as low as 1% across the genome and 0.1-0.5% in gene regions, as well as to estimate the population frequencies, haplotype backgrounds and linkage disequilibrium patterns of variant alleles.
Secondary goals will include the support of better SNP and probe selection for genotyping platforms in future studies and the improvement of the human reference sequence.
Furthermore, the completed database will be a useful tool for studying
regions under selection, variation in multiple populations and
understanding the underlying processes of mutation and recombination.
Outline
The human genome consists of approximately 3 billion DNA base pairs and is estimated to carry around 20,000 protein coding genes.
In designing the study the consortium needed to address several
critical issues regarding the project metrics such as technology
challenges, data quality standards and sequence coverage.
Over the course of the next three years, scientists at the Sanger Institute, BGI Shenzhen and the National Human Genome Research Institute’s
Large-Scale Sequencing Network are planning to sequence a minimum of
1,000 human genomes. Due to the large amount of sequence data that need
to be generated and analyzed it is possible that other participants may
be recruited over time.
Almost 10 billion bases will be sequenced per day over a period
of the two year production phase. This equates to more than two human
genomes every 24 hours; a groundbreaking capacity. Challenging the
leading experts of bioinformatics
and statistical genetics, the sequence dataset will comprise 6 trillion
DNA bases, 60-fold more sequence data than what has been published in DNA databases over the past 25 years.
To determine the final design of the full project three pilot
studies were designed and will be carried out within the first year of
the project. The first pilot intends to genotype 180 people of 3 major geographic groups
at low coverage (2x). For the second pilot study,
the genomes of two nuclear families (both parents and an adult child)
are going to be sequenced with deep coverage (20x per genome). The third
pilot study involves sequencing the coding regions (exons) of 1,000
genes in 1,000 people with deep coverage (20x).
It has been estimated that the project would likely cost more
than $500 million if standard DNA sequencing technologies were used.
Therefore, several new technologies (e.g. Solexa, 454, SOLiD)
will be applied, lowering the expected costs to between $30 million and
$50 million. The major support will be provided by the Wellcome Trust Sanger Institute in Hinxton, England; the Beijing Genomics Institute, Shenzhen (BGI Shenzhen), China; and the NHGRI, part of the National Institutes of Health (NIH).
Locations of population samples of 1000 Genomes Project. Each circle represents the number of sequences in the final release.
Based on the overall goals for the project, the samples will be chosen to provide power in populations where association studies
for common diseases are being carried out. Furthermore, the samples do
not need to have medical or phenotype information since the proposed
catalogue will be a basic resource on human variation.
For the pilot studies human genome samples from the HapMap collection will be sequenced. It will be useful to focus on samples that have additional data available (such as ENCODE sequence, genome-wide genotypes, fosmid-end sequence, structural variation assays, and gene expression) to be able to compare the results with those from other projects.
Complying with extensive ethical procedures, the 1000 Genomes
Project will then use samples from volunteer donors. The following
populations will be included in the study: Yoruba in Ibadan (YRI), Nigeria; Japanese in Tokyo (JPT); Chinese in Beijing (CHB); Utah residents with ancestry from northern and western Europe (CEU); Luhya in Webuye, Kenya (LWK); Maasai in Kinyawa, Kenya (MKK); Toscani in Italy (TSI); Peruvians in Lima, Peru (PEL); Gujarati Indians in Houston (GIH); Chinese in metropolitan Denver (CHD); people of Mexican ancestry in Los Angeles (MXL); and people of African ancestry in the southwestern United States (ASW).
Community meeting
Data
generated by the 1000 Genomes Project is widely used by the genetics
community, making the first 1000 Genomes Project one of the most cited
papers in biology.
To support this user community, the project held a community analysis
meeting in July 2012 that included talks highlighting key project
discoveries, their impact on population genetics and human disease
studies, and summaries of other large scale sequencing studies.
Project findings
Pilot phase
The pilot phase consisted of three projects:
low-coverage whole-genome sequencing of 179 individuals from 4 populations
high-coverage sequencing of 2 trios (mother-father-child)
exon-targeted sequencing of 697 individuals from 7 populations
It was found that on average, each person carries around 250-300
loss-of-function variants in annotated genes and 50-100 variants
previously implicated in inherited disorders. Based on the two trios, it
is estimated that the rate of de novo germline mutation is
approximately 10−8 per base per generation.
Metagenomics
allows the study of microbial communities like those present in this
stream receiving acid drainage from surface coal mining.
Metagenomics is the study of genetic material recovered directly from environmental samples. The broad field may also be referred to as environmental genomics, ecogenomics or community genomics.
While traditional microbiology and microbial genome sequencing and genomics rely upon cultivated clonalcultures, early environmental gene sequencing cloned specific genes (often the 16S rRNA gene) to produce a profile of diversity in a natural sample. Such work revealed that the vast majority of microbial biodiversity had been missed by cultivation-based methods.
Because of its ability to reveal the previously hidden diversity
of microscopic life, metagenomics offers a powerful lens for viewing the
microbial world that has the potential to revolutionize understanding
of the entire living world. As the price of DNA sequencing continues to fall, metagenomics now allows microbial ecology to be investigated at a much greater scale and detail than before. Recent studies use either "shotgun" or PCR directed sequencing to get largely unbiased samples of all genes from all the members of the sampled communities.
Etymology
The term "metagenomics" was first used by Jo Handelsman, Jon Clardy, Robert M. Goodman, Sean F. Brady, and others, and first appeared in publication in 1998.
The term metagenome referenced the idea that a collection of genes
sequenced from the environment could be analyzed in a way analogous to
the study of a single genome. In 2005, Kevin Chen and Lior Pachter (researchers at the University of California, Berkeley)
defined metagenomics as "the application of modern genomics technique
without the need for isolation and lab cultivation of individual
species".
History
Conventional sequencing begins with a culture of identical cells as a source of DNA.
However, early metagenomic studies revealed that there are probably
large groups of microorganisms in many environments that cannot be cultured and thus cannot be sequenced. These early studies focused on 16S ribosomalRNA sequences which are relatively short, often conserved within a species, and generally different between species. Many 16S rRNA sequences have been found which do not belong to any known cultured species,
indicating that there are numerous non-isolated organisms. These
surveys of ribosomal RNA (rRNA) genes taken directly from the
environment revealed that cultivation based methods find less than 1% of the bacterial and archaeal species in a sample.
Much of the interest in metagenomics comes from these discoveries that
showed that the vast majority of microorganisms had previously gone
unnoticed.
Early molecular work in the field was conducted by Norman R. Pace and colleagues, who used PCR to explore the diversity of ribosomal RNA sequences.
The insights gained from these breakthrough studies led Pace to propose
the idea of cloning DNA directly from environmental samples as early as
1985. This led to the first report of isolating and cloning bulk DNA from an environmental sample, published by Pace and colleagues in 1991 while Pace was in the Department of Biology at Indiana University. Considerable efforts ensured that these were not PCR
false positives and supported the existence of a complex community of
unexplored species. Although this methodology was limited to exploring
highly conserved, non-protein coding genes,
it did support early microbial morphology-based observations that
diversity was far more complex than was known by culturing methods. Soon
after that, Healy reported the metagenomic isolation of functional
genes from "zoolibraries" constructed from a complex culture of
environmental organisms grown in the laboratory on dried grasses in 1995. After leaving the Pace laboratory, Edward DeLong
continued in the field and has published work that has largely laid the
groundwork for environmental phylogenies based on signature 16S
sequences, beginning with his group's construction of libraries from marine samples.
In 2002, Mya Breitbart, Forest Rohwer,
and colleagues used environmental shotgun sequencing (see below) to
show that 200 liters of seawater contains over 5000 different viruses. Subsequent studies showed that there are more than a thousand viral species in human stool and possibly a million different viruses per kilogram of marine sediment, including many bacteriophages. Essentially all of the viruses in these studies were new species. In 2004, Gene Tyson, Jill Banfield, and colleagues at the University of California, Berkeley and the Joint Genome Institute sequenced DNA extracted from an acid mine drainage system. This effort resulted in the complete, or nearly complete, genomes for a handful of bacteria and archaea that had previously resisted attempts to culture them.
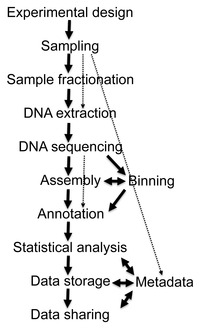
Flow diagram of a typical metagenome project
Beginning in 2003, Craig Venter, leader of the privately funded parallel of the Human Genome Project, has led the Global Ocean Sampling Expedition
(GOS), circumnavigating the globe and collecting metagenomic samples
throughout the journey. All of these samples are sequenced using shotgun
sequencing, in hopes that new genomes (and therefore new organisms)
would be identified. The pilot project, conducted in the Sargasso Sea, found DNA from nearly 2000 different species, including 148 types of bacteria never before seen. Venter has circumnavigated the globe and thoroughly explored the West Coast of the United States, and completed a two-year expedition to explore the Baltic, Mediterranean and Black
Seas. Analysis of the metagenomic data collected during this journey
revealed two groups of organisms, one composed of taxa adapted to
environmental conditions of 'feast or famine', and a second composed of
relatively fewer but more abundantly and widely distributed taxa
primarily composed of plankton.
Environmental
Shotgun Sequencing (ESS). (A) Sampling from habitat; (B) filtering
particles, typically by size; (C) Lysis and DNA extraction; (D) cloning
and library construction; (E) sequencing the clones; (F) sequence
assembly into contigs and scaffolds.
Shotgun metagenomics
Advances in bioinformatics,
refinements of DNA amplification, and the proliferation of
computational power have greatly aided the analysis of DNA sequences
recovered from environmental samples, allowing the adaptation of shotgun sequencing
to metagenomic samples (known also as whole metagenome shotgun or WMGS
sequencing). The approach, used to sequence many cultured microorganisms
and the human genome, randomly shears DNA, sequences many short sequences, and reconstructs them into a consensus sequence.
Shotgun sequencing reveals genes present in environmental samples.
Historically, clone libraries were used to facilitate this sequencing.
However, with advances in high throughput sequencing technologies, the
cloning step is no longer necessary and greater yields of sequencing
data can be obtained without this labour-intensive bottleneck step.
Shotgun metagenomics provides information both about which organisms are
present and what metabolic processes are possible in the community.
Because the collection of DNA from an environment is largely
uncontrolled, the most abundant organisms in an environmental sample are
most highly represented in the resulting sequence data. To achieve the
high coverage needed to fully resolve the genomes of under-represented
community members, large samples, often prohibitively so, are needed. On
the other hand, the random nature of shotgun sequencing ensures that
many of these organisms, which would otherwise go unnoticed using
traditional culturing techniques, will be represented by at least some
small sequence segments. An emerging approach combines shotgun sequencing and chromosome conformation capture (Hi-C), which measures the proximity of any two DNA sequences within the same cell, to guide microbial genome assembly.
High-throughput sequencing
The first metagenomic studies conducted using high-throughput sequencing used massively parallel 454 pyrosequencing. Three other technologies commonly applied to environmental sampling are the Ion Torrent Personal Genome Machine, the Illumina MiSeq or HiSeq and the Applied Biosystems SOLiD system. These techniques for sequencing DNA generate shorter fragments than Sanger sequencing;
Ion Torrent PGM System and 454 pyrosequencing typically produces
~400 bp reads, Illumina MiSeq produces 400-700bp reads (depending on
whether paired end options are used), and SOLiD produce 25–75 bp reads.
Historically, these read lengths were significantly shorter than the
typical Sanger sequencing read length of ~750 bp, however the Illumina
technology is quickly coming close to this benchmark. However, this
limitation is compensated for by the much larger number of sequence
reads. In 2009, pyrosequenced metagenomes generate 200–500 megabases,
and Illumina platforms generate around 20–50 gigabases, but these
outputs have increased by orders of magnitude in recent years.
An additional advantage to high throughput sequencing is that this
technique does not require cloning the DNA before sequencing, removing
one of the main biases and bottlenecks in environmental sampling.
Bioinformatics
The
data generated by metagenomics experiments are both enormous and
inherently noisy, containing fragmented data representing as many as
10,000 species. The sequencing of the cow rumen metagenome generated 279 gigabases, or 279 billion base pairs of nucleotide sequence data, while the human gut microbiome gene catalog identified 3.3 million genes assembled from 567.7 gigabases of sequence data.
Collecting, curating, and extracting useful biological information from
datasets of this size represent significant computational challenges
for researchers.
Sequence pre-filtering
The
first step of metagenomic data analysis requires the execution of
certain pre-filtering steps, including the removal of redundant,
low-quality sequences and sequences of probable eukaryotic origin (especially in metagenomes of human origin). The methods available for the removal of contaminating eukaryotic genomic DNA sequences include Eu-Detect and DeConseq.
Assembly
DNA sequence data from genomic and metagenomic projects are essentially the same, but genomic sequence data offers higher coverage while metagenomic data is usually highly non-redundant.
Furthermore, the increased use of second-generation sequencing
technologies with short read lengths means that much of future
metagenomic data will be error-prone. Taken in combination, these
factors make the assembly of metagenomic sequence reads into genomes
difficult and unreliable. Misassemblies are caused by the presence of repetitive DNA sequences that make assembly especially difficult because of the difference in the relative abundance of species present in the sample. Misassemblies can also involve the combination of sequences from more than one species into chimeric contigs.
There are several assembly programs, most of which can use information from paired-end tags in order to improve the accuracy of assemblies. Some programs, such as Phrap or Celera Assembler, were designed to be used to assemble single genomes but nevertheless produce good results when assembling metagenomic data sets. Other programs, such as Velvet assembler, have been optimized for the shorter reads produced by second-generation sequencing through the use of de Bruijn graphs.
The use of reference genomes allows researchers to improve the assembly
of the most abundant microbial species, but this approach is limited by
the small subset of microbial phyla for which sequenced genomes are
available.
After an assembly is created, an additional challenge is "metagenomic
deconvolution", or determining which sequences come from which species
in the sample.
Gene prediction
Metagenomic analysis pipelines use two approaches in the annotation of coding regions in the assembled contigs. The first approach is to identify genes based upon homology with genes that are already publicly available in sequence databases, usually by BLAST searches. This type of approach is implemented in the program MEGAN4. The second, ab initio,
uses intrinsic features of the sequence to predict coding regions based
upon gene training sets from related organisms. This is the approach
taken by programs such as GeneMark and GLIMMER. The main advantage of ab initio
prediction is that it enables the detection of coding regions that lack
homologs in the sequence databases; however, it is most accurate when
there are large regions of contiguous genomic DNA available for
comparison.
Gene annotations provide the "what", while measurements of species diversity provide the "who". In order to connect community composition and function in metagenomes, sequences must be binned. Binning is the process of associating a particular sequence with an organism. In similarity-based binning, methods such as BLAST
are used to rapidly search for phylogenetic markers or otherwise
similar sequences in existing public databases. This approach is
implemented in MEGAN. Another tool, PhymmBL, uses interpolated Markov models to assign reads. MetaPhlAn and AMPHORA
are methods based on unique clade-specific markers for estimating
organismal relative abundances with improved computational performances. Other tools, like mOTUs and MetaPhyler, use universal marker genes to profile prokaryotic species. With the mOTUs profiler is possible to profile species without a reference genome, improving the estimation of microbial community diversity. Recent methods, such as SLIMM,
use read coverage landscape of individual reference genomes to minimize
false-positive hits and get reliable relative abundances. In composition based binning, methods use intrinsic features of the sequence, such as oligonucleotide frequencies or codon usage bias. Once sequences are binned, it is possible to carry out comparative analysis of diversity and richness.
Data integration
The massive amount of exponentially growing sequence data is a daunting challenge that is complicated by the complexity of the metadata
associated with metagenomic projects. Metadata includes detailed
information about the three-dimensional (including depth, or height)
geography and environmental features of the sample, physical data about
the sample site, and the methodology of the sampling. This information is necessary both to ensure replicability
and to enable downstream analysis. Because of its importance, metadata
and collaborative data review and curation require standardized data
formats located in specialized databases, such as the Genomes OnLine
Database (GOLD).
Several tools have been developed to integrate metadata and
sequence data, allowing downstream comparative analyses of different
datasets using a number of ecological indices. In 2007, Folker Meyer and
Robert Edwards and a team at Argonne National Laboratory and the University of Chicago released the Metagenomics Rapid Annotation using Subsystem Technology server (MG-RAST) a community resource for metagenome data set analysis. As of June 2012 over 14.8 terabases (14x1012
bases) of DNA have been analyzed, with more than 10,000 public data
sets freely available for comparison within MG-RAST. Over 8,000 users
now have submitted a total of 50,000 metagenomes to MG-RAST. The Integrated Microbial Genomes/Metagenomes
(IMG/M) system also provides a collection of tools for functional
analysis of microbial communities based on their metagenome sequence,
based upon reference isolate genomes included from the Integrated Microbial Genomes (IMG) system and the Genomic Encyclopedia of Bacteria and Archaea (GEBA) project.
One of the first standalone tools for analysing high-throughput metagenome shotgun data was MEGAN (MEta Genome ANalyzer).
A first version of the program was used in 2005 to analyse the
metagenomic context of DNA sequences obtained from a mammoth bone.
Based on a BLAST comparison against a reference database, this tool
performs both taxonomic and functional binning, by placing the reads
onto the nodes of the NCBI taxonomy using a simple lowest common
ancestor (LCA) algorithm or onto the nodes of the SEED or KEGG classifications, respectively.
With the advent of fast and inexpensive sequencing instruments,
the growth of databases of DNA sequences is now exponential (e.g., the
NCBI GenBank database ).
Faster and efficient tools are needed to keep pace with the
high-throughput sequencing, because the BLAST-based approaches such as
MG-RAST or MEGAN run slowly to annotate large samples (e.g., several
hours to process a small/medium size dataset/sample).
Thus, ultra-fast classifiers have recently emerged, thanks to more
affordable powerful servers. These tools can perform the taxonomic
annotation at extremely high speed, for example CLARK (according to CLARK's authors, it can classify accurately "32 million
metagenomic short reads per minute"). At such a speed, a very large
dataset/sample of a billion short reads can be processed in about 30
minutes.
With the increasing availability of samples containing ancient
DNA and due to the uncertainty associated with the nature of those
samples (ancient DNA damage), FALCON,
a fast tool capable of producing conservative similarity estimates has
been made available. According to FALCON's authors, it can use relaxed
thresholds and edit distances without affecting the memory and speed
performance.
Comparative metagenomics
Comparative
analyses between metagenomes can provide additional insight into the
function of complex microbial communities and their role in host health. Pairwise or multiple comparisons between metagenomes can be made at the level of sequence composition (comparing GC-content
or genome size), taxonomic diversity, or functional complement.
Comparisons of population structure and phylogenetic diversity can be
made on the basis of 16S and other phylogenetic marker genes, or—in the
case of low-diversity communities—by genome reconstruction from the
metagenomic dataset. Functional comparisons between metagenomes may be made by comparing sequences against reference databases such as COG or KEGG, and tabulating the abundance by category and evaluating any differences for statistical significance. This gene-centric approach emphasizes the functional complement of the community
as a whole rather than taxonomic groups, and shows that the functional
complements are analogous under similar environmental conditions.
Consequently, metadata on the environmental context of the metagenomic
sample is especially important in comparative analyses, as it provides
researchers with the ability to study the effect of habitat upon
community structure and function.
Additionally, several studies have also utilized oligonucleotide
usage patterns to identify the differences across diverse microbial
communities. Examples of such methodologies include the dinucleotide
relative abundance approach by Willner et al. and the HabiSign approach of Ghosh et al.
This latter study also indicated that differences in tetranucleotide
usage patterns can be used to identify genes (or metagenomic reads)
originating from specific habitats. Additionally some methods as
TriageTools or Compareads detect similar reads between two read sets. The similarity measure they apply on reads is based on a number of identical words of length k shared by pairs of reads.
A key goal in comparative metagenomics is to identify microbial
group(s) which are responsible for conferring specific characteristics
to a given environment. However, due to issues in the sequencing
technologies artifacts need to be accounted for like in metagenomeSeq. Others have characterized inter-microbial interactions between the resident microbial groups. A GUI-based comparative metagenomic analysis application called Community-Analyzer has been developed by Kuntal et al.
which implements a correlation-based graph layout algorithm that not
only facilitates a quick visualization of the differences in the
analyzed microbial communities (in terms of their taxonomic
composition), but also provides insights into the inherent
inter-microbial interactions occurring therein. Notably, this layout
algorithm also enables grouping of the metagenomes based on the probable
inter-microbial interaction patterns rather than simply comparing
abundance values of various taxonomic groups. In addition, the tool
implements several interactive GUI-based functionalities that enable
users to perform standard comparative analyses across microbiomes.
Data analysis
Community metabolism
In many bacterial communities, natural or engineered (such as bioreactors), there is significant division of labor in metabolism (Syntrophy), during which the waste products of some organisms are metabolites for others. In one such system, the methanogenic bioreactor, functional stability requires the presence of several syntrophic species (Syntrophobacterales and Synergistia) working together in order to turn raw resources into fully metabolized waste (methane). Using comparative gene studies and expression experiments with microarrays or proteomics
researchers can piece together a metabolic network that goes beyond
species boundaries. Such studies require detailed knowledge about which
versions of which proteins are coded by which species and even by which
strains of which species. Therefore, community genomic information is
another fundamental tool (with metabolomics and proteomics) in the quest to determine how metabolites are transferred and transformed by a community.
Metagenomics allows researchers to access the functional and
metabolic diversity of microbial communities, but it cannot show which
of these processes are active. The extraction and analysis of metagenomic mRNA (the metatranscriptome) provides information on the regulation and expression profiles of complex communities. Because of the technical difficulties (the short half-life of mRNA, for example) in the collection of environmental RNA there have been relatively few in situ metatranscriptomic studies of microbial communities to date. While originally limited to microarray technology, metatranscriptomics studies have made use of transcriptomics technologies to measure whole-genome expression and quantification of a microbial community, first employed in analysis of ammonia oxidation in soils.
Viruses
Metagenomic sequencing is particularly useful in the study of viral
communities. As viruses lack a shared universal phylogenetic marker (as 16S RNA for bacteria and archaea, and 18S RNA
for eukarya), the only way to access the genetic diversity of the viral
community from an environmental sample is through metagenomics. Viral
metagenomes (also called viromes) should thus provide more and more
information about viral diversity and evolution. For example, a metagenomic pipeline called Giant Virus Finder showed the first evidence of existence of giant viruses in a saline desert and in Antarctic dry valleys.
The soils in which plants grow are inhabited by microbial communities, with one gram of soil containing around 109-1010 microbial cells which comprise about one gigabase of sequence information.
The microbial communities which inhabit soils are some of the most
complex known to science, and remain poorly understood despite their
economic importance. Microbial consortia perform a wide variety of ecosystem services necessary for plant growth, including fixing atmospheric nitrogen, nutrient cycling, disease suppression, and sequesteriron and other metals.
Functional metagenomics strategies are being used to explore the
interactions between plants and microbes through cultivation-independent
study of these microbial communities.
By allowing insights into the role of previously uncultivated or rare
community members in nutrient cycling and the promotion of plant growth,
metagenomic approaches can contribute to improved disease detection in crops and livestock and the adaptation of enhanced farming practices which improve crop health by harnessing the relationship between microbes and plants.
The efficient industrial-scale deconstruction of biomass requires novel enzymes with higher productivity and lower cost. Metagenomic approaches to the analysis of complex microbial communities allow the targeted screening of enzymes with industrial applications in biofuel production, such as glycoside hydrolases.
Furthermore, knowledge of how these microbial communities function is
required to control them, and metagenomics is a key tool in their
understanding. Metagenomic approaches allow comparative analyses between
convergent microbial systems like biogas fermenters or insectherbivores such as the fungus garden of the leafcutter ants.
Biotechnology
Microbial communities produce a vast array of biologically active chemicals that are used in competition and communication.
Many of the drugs in use today were originally uncovered in microbes;
recent progress in mining the rich genetic resource of non-culturable
microbes has led to the discovery of new genes, enzymes, and natural
products. The application of metagenomics has allowed the development of commodity and fine chemicals, agrochemicals and pharmaceuticals where the benefit of enzyme-catalyzedchiral synthesis is increasingly recognized.
Two types of analysis are used in the bioprospecting
of metagenomic data: function-driven screening for an expressed trait,
and sequence-driven screening for DNA sequences of interest.
Function-driven analysis seeks to identify clones expressing a desired
trait or useful activity, followed by biochemical characterization and
sequence analysis. This approach is limited by availability of a
suitable screen and the requirement that the desired trait be expressed
in the host cell. Moreover, the low rate of discovery (less than one per
1,000 clones screened) and its labor-intensive nature further limit
this approach. In contrast, sequence-driven analysis uses conserved DNA sequences to design PCR primers to screen clones for the sequence of interest.
In comparison to cloning-based approaches, using a sequence-only
approach further reduces the amount of bench work required. The
application of massively parallel sequencing also greatly increases the
amount of sequence data generated, which require high-throughput
bioinformatic analysis pipelines.
The sequence-driven approach to screening is limited by the breadth and
accuracy of gene functions present in public sequence databases. In
practice, experiments make use of a combination of both functional and
sequence-based approaches based upon the function of interest, the
complexity of the sample to be screened, and other factors. An example of success using metagenomics as a biotechnology for drug discovery is illustrated with the malacidin antibiotics.
Ecology
Metagenomics can provide valuable insights into the functional ecology of environmental communities.
Metagenomic analysis of the bacterial consortia found in the
defecations of Australian sea lions suggests that nutrient-rich sea lion
faeces may be an important nutrient source for coastal ecosystems. This
is because the bacteria that are expelled simultaneously with the
defecations are adept at breaking down the nutrients in the faeces into a
bioavailable form that can be taken up into the food chain.
DNA sequencing can also be used more broadly to identify species present in a body of water, debris filtered from the air, or sample of dirt. This can establish the range of invasive species and endangered species, and track seasonal populations.
Environmental remediation
Metagenomics can improve strategies for monitoring the impact of pollutants on ecosystems
and for cleaning up contaminated environments. Increased understanding
of how microbial communities cope with pollutants improves assessments
of the potential of contaminated sites to recover from pollution and
increases the chances of bioaugmentation or biostimulation trials to succeed.
Gut microbe characterization
Microbial communities play a key role in preserving human health, but their composition and the mechanism by which they do so remains mysterious.
Metagenomic sequencing is being used to characterize the microbial
communities from 15–18 body sites from at least 250 individuals. This is
part of the Human Microbiome initiative with primary goals to determine if there is a core human microbiome,
to understand the changes in the human microbiome that can be
correlated with human health, and to develop new technological and bioinformatics tools to support these goals.
Another medical study as part of the MetaHit (Metagenomics of the
Human Intestinal Tract) project consisted of 124 individuals from
Denmark and Spain consisting of healthy, overweight, and irritable bowel
disease patients. The study attempted to categorize the depth and
phylogenetic diversity of gastrointestinal bacteria. Using Illumina GA
sequence data and SOAPdenovo, a de Bruijn graph-based tool specifically
designed for assembly short reads, they were able to generate 6.58
million contigs greater than 500 bp for a total contig length of 10.3 Gb
and a N50 length of 2.2 kb.
The study demonstrated that two bacterial divisions,
Bacteroidetes and Firmicutes, constitute over 90% of the known
phylogenetic categories that dominate distal gut bacteria. Using the
relative gene frequencies found within the gut these researchers
identified 1,244 metagenomic clusters that are critically important for
the health of the intestinal tract. There are two types of functions in
these range clusters: housekeeping and those specific to the intestine.
The housekeeping gene clusters are required in all bacteria and are
often major players in the main metabolic pathways including central
carbon metabolism and amino acid synthesis. The gut-specific functions
include adhesion to host proteins and the harvesting of sugars from
globoseries glycolipids. Patients with irritable bowel syndrome were
shown to exhibit 25% fewer genes and lower bacterial diversity than
individuals not suffering from irritable bowel syndrome indicating that
changes in patients' gut biome diversity may be associated with this
condition.
While these studies highlight some potentially valuable medical
applications, only 31–48.8% of the reads could be aligned to 194 public
human gut bacterial genomes and 7.6–21.2% to bacterial genomes available
in GenBank which indicates that there is still far more research
necessary to capture novel bacterial genomes.
Infectious disease diagnosis
Differentiating
between infectious and non-infectious illness, and identifying the
underlying etiology of infection, can be quite challenging. For example,
more than half of cases of encephalitis
remain undiagnosed, despite extensive testing using state-of-the-art
clinical laboratory methods. Metagenomic sequencing shows promise as a
sensitive and rapid method to diagnose infection by comparing genetic
material found in a patient's sample to a database of thousands of
bacteria, viruses, and other pathogens