| https://en.wikipedia.org/wiki/Feature-oriented_programming |
|---|
In computer programming, feature-oriented programming (FOP) or feature-oriented software development (FOSD) is a programming paradigm for program generation in software product lines (SPLs) and for incremental development of programs.
History

FOSD arose out of layer-based designs and levels of abstraction in network protocols and extensible database systems in the late-1980s. A program was a stack of layers. Each layer added functionality to previously composed layers and different compositions of layers produced different programs. Not surprisingly, there was a need for a compact language to express such designs. Elementary algebra fit the bill: each layer was a function (a program transformation) that added new code to an existing program to produce a new program, and a program's design was modeled by an expression, i.e., a composition of transformations (layers). The figure to the left illustrates the stacking of layers i, j, and h (where h is on the bottom and i is on the top). The algebraic notations i(j(h)), i•j•h, and i+j+h have been used to express these designs.
Over time, layers were equated to features, where a feature is an increment in program functionality. The paradigm for program design and generation was recognized to be an outgrowth of relational query optimization, where query evaluation programs were defined as relational algebra expressions, and query optimization was expression optimization. A software product line is a family of programs where each program is defined by a unique composition of features. FOSD has since evolved into the study of feature modularity, tools, analyses, and design techniques to support feature-based program generation.
The second generation of FOSD research was on feature interactions, which originated in telecommunications. Later, the term feature-oriented programming was coined; this work exposed interactions between layers. Interactions require features to be adapted when composed with other features.
A third generation of research focussed on the fact that every program has multiple representations (e.g., source, makefiles, documentation, etc.) and adding a feature to a program should elaborate each of its representations so that all are consistent. Additionally, some of representations could be generated (or derived) from others. In the sections below, the mathematics of the three most recent generations of FOSD, namely GenVoca, AHEAD, and FOMDD are described, and links to product lines that have been developed using FOSD tools are provided. Also, four additional results that apply to all generations of FOSD are: FOSD metamodels, FOSD program cubes, and FOSD feature interactions.
GenVoca
GenVoca (a portmanteau of the names Genesis and Avoca) is a compositional paradigm for defining programs of product lines. Base programs are 0-ary functions or transformations called values:
f -- base program with feature f h -- base program with feature h
and features are unary functions/transformations that elaborate (modify, extend, refine) a program:
i + x -- adds feature i to program x j + x -- adds feature j to program x
where + denotes function composition. The design of a program is a named expression, e.g.:
p1 = j + f -- program p1 has features j and f p2 = j + h -- program p2 has features j and h p3 = i + j + h -- program p3 has features i, j, and h
A GenVoca model of a domain or software product line is a collection of base programs and features (see MetaModels and Program Cubes). The programs (expressions) that can be created defines a product line. Expression optimization is program design optimization, and expression evaluation is program generation.
- Note: GenVoca is based on the stepwise development of programs: a process that emphasizes design simplicity and understandability, which are key to program comprehension and automated program construction. Consider program p3 above: it begins with base program h, then feature j is added (read: the functionality of feature j is added to the codebase of h), and finally feature i is added (read: the functionality of feature i is added to the codebase of j•h).
- Note: not all combinations of features are meaningful. Feature models (which can be translated into propositional formulas) are graphical representations that define legal combinations of features.
- Note: A more recent formulation of GenVoca is symmetric: there is only one base program, 0 (the empty program), and all features are unary functions. This suggests the interpretation that GenVoca composes program structures by superposition, the idea that complex structures are composed by superimposing simpler structures. Yet another reformulation of GenVoca is as a monoid: a GenVoca model is a set of features with a composition operation (•); composition is associative and there is an identity element (namely 1, the identity function). Although all compositions are possible, not all are meaningful. That's the reason for feature models.
GenVoca features were originally implemented using C preprocessor (#ifdef feature ... #endif) techniques. A more advanced technique, called mixin layers, showed the connection of features to object-oriented collaboration-based designs.
AHEAD
Algebraic Hierarchical Equations for Application Design (AHEAD) generalized GenVoca in two ways. First, it revealed the internal structure of GenVoca values as tuples. Every program has multiple representations, such as source, documentation, bytecode, and makefiles. A GenVoca value is a tuple of program representations. In a product line of parsers, for example, a base parser f is defined by its grammar gf, Java source sf, and documentation df. Parser f is modeled by the tuple f=[gf, sf, df]. Each program representation may have subrepresentations, and they too may have subrepresentations, recursively. In general, a GenVoca value is a tuple of nested tuples that define a hierarchy of representations for a particular program.
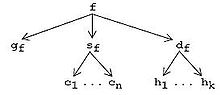
Hierarchical relationships among program artifacts

Example. Suppose terminal representations are files. In AHEAD, grammar gf corresponds to a single BNF file, source sf corresponds to a tuple of Java files [c1…cn], and documentation df is a tuple of HTML files [h1…hk]. A GenVoca value (nested tuples) can be depicted as a directed graph: the graph for parser f is shown in the figure to the right. Arrows denote projections, i.e., mappings from a tuple to one of its components. AHEAD implements tuples as file directories, so f is a directory containing file gf and subdirectories sf and df. Similarly, directory sf contains files c1…cn, and directory df contains files h1…hk.
- Note: Files can be hierarchically decomposed further. Each Java class can be decomposed into a tuple of members and other class declarations (e.g., initialization blocks, etc.). The important idea here is that the mathematics of AHEAD are recursive.
Second, AHEAD expresses features as nested tuples of unary functions called deltas. Deltas can be program refinements (semantics-preserving transformations), extensions (semantics-extending transformations), or interactions (semantics-altering transformations). We use the neutral term “delta” to represent all of these possibilities, as each occurs in FOSD.
To illustrate, suppose feature j extends a grammar by Δgj (new rules and tokens are added), extends source code by Δsj (new classes and members are added and existing methods are modified), and extends documentation by Δdj. The tuple of deltas for feature j is modeled by j=[Δgj,Δsj,Δdj], which we call a delta tuple. Elements of delta tuples can themselves be delta tuples. Example: Δsj represents the changes that are made to each class in sf by feature j, i.e., Δsj=[Δc1…Δcn]. The representations of a program are computed recursively by nested vector addition. The representations for parser p2 (whose GenVoca expression is j+f) are:
p2 = j + f -- GenVoca expression
= [Δgj, Δsj, Δdj] + [gf, sf, df] -- substitution
= [Δgj+gf, Δsj+sf, Δdj+df] -- compose tuples element-wise
That is, the grammar of p2 is the base grammar composed with its extension (Δgj+gf), the source of p2 is the base source composed with its extension (Δsj+sf), and so on. As elements of delta tuples can themselves be delta tuples, composition recurses, e.g., Δsj+sf= [Δc1…Δcn]+[c1…cn]=[Δc1+c1…Δcn+cn]. Summarizing, GenVoca values are nested tuples of program artifacts, and features are nested delta tuples, where + recursively composes them by vector addition. This is the essence of AHEAD.
The ideas presented above concretely expose two FOSD principles. The Principle of Uniformity states that all program artifacts are treated and modified in the same way. (This is evidenced by deltas for different artifact types above). The Principle of Scalability states all levels of abstractions are treated uniformly. (This gives rise to the hierarchical nesting of tuples above).
The original implementation of AHEAD is the AHEAD Tool Suite and Jak language, which exhibits both the Principles of Uniformity and Scalability. Next-generation tools include CIDE and FeatureHouse.
FOMDD

Feature-Oriented Model-Driven Design (FOMDD) combines the ideas of AHEAD with Model-Driven Design (MDD) (a.k.a. Model-Driven Architecture (MDA)). AHEAD functions capture the lockstep update of program artifacts when a feature is added to a program. But there are other functional relationships among program artifacts that express derivations. For example, the relationship between a grammar gf and its parser source sf is defined by a compiler-compiler tool, e.g., javacc. Similarly, the relationship between Java source sf and its bytecode bf is defined by the javac compiler. A commuting diagram expresses these relationships. Objects are program representations, downward arrows are derivations, and horizontal arrows are deltas. The figure to the right shows the commuting diagram for program p3 = i+j+h = [g3,s3,b3].
A fundamental property of a commuting diagram is that all paths between two objects are equivalent. For example, one way to derive the bytecode b3 of parser p3 (lower right object in the figure to the right) from grammar gh of parser h (upper left object) is to derive the bytecode bh and refine to b3, while another way refines gh to g3, and then derive b3, where + represents delta composition and () is function or tool application:
There are possible paths to derive the bytecode b3 of parser p3 from the grammar gh of parser h. Each path represents a metaprogram whose execution generates the target object (b3) from the starting object (gf). There is a potential optimization: traversing each arrow of a commuting diagram has a cost. The cheapest (i.e., shortest) path between two objects in a commuting diagram is a geodesic, which represents the most efficient metaprogram that produces the target object from a given object.

- Note: A “cost metric” need not be a monetary value; cost may be measured in production time, peak or total memory requirements, power consumption, or some informal metric like “ease of explanation”, or a combination of the above (e.g., multi-objective optimization). The idea of a geodesic is general, and should be understood and appreciated from this more general context.
- Note: It is possible for there to be m starting objects and n ending objects in a geodesic; when m=1 and n>1, this is the Directed Steiner Tree Problem, which is NP-hard.
Commuting diagrams are important for at least two reasons: (1) there is the possibility of optimizing the generation of artifacts (e.g., geodesics) and (2) they specify different ways of constructing a target object from a starting object. A path through a diagram corresponds to a tool chain: for an FOMDD model to be consistent, it should be proven (or demonstrated through testing) that all tool chains that map one object to another in fact yield equivalent results. If this is not the case, then either there is a bug in one or more of the tools or the FOMDD model is wrong.



