In
biology, a
mutation is a permanent change of the
nucleotide sequence of the
genome of an
organism,
virus, or
extrachromosomal DNA or other genetic elements. Mutations result from damage to DNA which is not
repaired or to RNA genomes (typically caused by radiation or chemical
mutagens), errors in the process of
replication, or from the insertion or deletion of segments of DNA by
mobile genetic elements.
[1][2][3] Mutations may or may not produce discernible changes in the observable characteristics (
phenotype) of an organism. Mutations play a part in both normal and abnormal biological processes including:
evolution,
cancer, and the development of the immune system, including
junctional diversity.
Mutation can result in several different types of change in sequences. Mutations in genes can either have no effect, alter the
product of a gene, or prevent the gene from functioning properly or completely. Mutations can also occur in nongenic regions. One study on genetic variations between different species of
Drosophila suggests that, if a mutation changes a
protein produced by a gene, the result is likely to be harmful, with an estimated 70 percent of amino acid
polymorphisms that have damaging effects, and the remainder being either neutral or weakly beneficial.
[4] Due to the damaging effects that mutations can have on genes, organisms have mechanisms such as
DNA repair to prevent or correct (revert the mutated sequence back to its original state) mutations.
[1]
Description
Mutations can involve the
duplication of large sections of DNA, usually through
genetic recombination.
[5] These duplications are a major source of raw material for evolving new genes, with tens to hundreds of genes duplicated in animal genomes every million years.
[6] Most genes belong to larger
families of genes of
shared ancestry.
[7] Novel genes are produced by several methods, commonly through the duplication and mutation of an ancestral gene, or by recombining parts of different genes to form new combinations with new functions.
[8][9]
Here,
domains act as modules, each with a particular and independent function, that can be mixed together to produce genes encoding new proteins with novel properties.
[10] For example, the human eye uses four genes to make structures that sense light: three for
color vision and one for
night vision; all four arose from a single ancestral gene.
[11] Another advantage of duplicating a gene (or even an
entire genome) is that this increases
redundancy; this allows one gene in the pair to acquire a new function while the other copy performs the original function.
[12][13]
Other types of mutation occasionally create new genes from previously noncoding DNA.
[14][15]
Changes in
chromosome number may involve even larger mutations, where segments of the DNA within chromosomes break and then rearrange. For example, in the
Homininae, two chromosomes fused to produce human
chromosome 2; this fusion did not occur in the
lineage of the other apes, and they retain these separate chromosomes.
[16] In evolution, the most important role of such chromosomal rearrangements may be to accelerate the divergence of a population into new species by making populations less likely to interbreed, thereby preserving genetic differences between these populations.
[17]
Sequences of DNA that can move about the genome, such as
transposons, make up a major fraction of the genetic material of plants and animals, and may have been important in the evolution of genomes.
[18] For example, more than a million copies of the
Alu sequence are present in the
human genome, and these sequences have now been recruited to perform functions such as regulating
gene expression.
[19] Another effect of these mobile DNA sequences is that when they move within a genome, they can mutate or delete existing genes and thereby produce genetic diversity.
[2]
Nonlethal mutations accumulate within the
gene pool and increase the amount of genetic variation.
[20] The abundance of some genetic changes within the gene pool can be reduced by
natural selection, while other "more favorable" mutations may accumulate and result in adaptive changes.
For example, a butterfly may produce offspring with new mutations. The majority of these mutations will have no effect; but one might change the color of one of the butterfly's offspring, making it harder (or easier) for predators to see. If this color change is advantageous, the chance of this butterfly's surviving and producing its own offspring are a little better, and over time the number of butterflies with this mutation may form a larger percentage of the population.
Neutral mutations are defined as mutations whose effects do not influence the
fitness of an individual. These can accumulate over time due to
genetic drift. It is believed that the overwhelming majority of mutations have no significant effect on an organism's fitness.
[citation needed] Also,
DNA repair mechanisms are able to mend most changes before they become permanent mutations, and many organisms have mechanisms for eliminating otherwise-permanently mutated
somatic cells.
Beneficial mutations can improve reproductive success.
Causes
Four classes of mutations are (1) spontaneous mutations (molecular decay), (2) mutations due to error prone replication bypass of
naturally occurring DNA damage (also called error prone
translesion synthesis), (3) errors introduced during DNA repair, and (4) induced mutations caused by
mutagens. Scientists may also deliberately introduce mutant sequences through DNA manipulation for the sake of scientific experimentation.
Spontaneous mutation
Spontaneous mutations on the molecular level can be caused by:
[21]
- Tautomerism — A base is changed by the repositioning of a hydrogen atom, altering the hydrogen bonding pattern of that base, resulting in incorrect base pairing during replication.
- Depurination — Loss of a purine base (A or G) to form an apurinic site (AP site).
- Deamination — Hydrolysis changes a normal base to an atypical base containing a keto group in place of the original amine group. Examples include C → U and A → HX (hypoxanthine), which can be corrected by DNA repair mechanisms; and 5MeC (5-methylcytosine) → T, which is less likely to be detected as a mutation because thymine is a normal DNA base.
- Slipped strand mispairing — Denaturation of the new strand from the template during replication, followed by renaturation in a different spot ("slipping"). This can lead to insertions or deletions.
Error prone replication by-pass
There is increasing evidence that the majority of spontaneously arising mutations are due to error prone replication (
translesion synthesis) past a DNA damage in the template strand. As described in the article
DNA damage (naturally occurring), naturally occurring DNA damages arise about 60,000 to 100,000 times per day per mammalian cell. In mice, the majority of mutations are caused by translesion synthesis.
[22] Likewise, in yeast, Kunz et al.
[23] found that less than 60% of the spontaneous single base pair substitutions and deletions were caused by translesion synthesis.
Errors introduced during DNA repair
Although naturally occurring double-strand breaks occur at a relatively low frequency in DNA (see
DNA damage (naturally occurring)) their repair often causes mutation.
Non-homologous end joining (NHEJ) is a major pathway for repairing double-strand breaks. NHEJ involves removal of a few nucleotides to allow somewhat inaccurate alignment of the two ends for rejoining followed by addition of nucleotides to fill in gaps. As a consequence, NHEJ often introduces mutations.
[24]
Induced mutation
Induced mutations on the molecular level can be caused by:-
- Chemicals
- Hydroxylamine NH
2OH
- Base analogs (e.g., BrdU)
- Alkylating agents (e.g., N-ethyl-N-nitrosourea) These agents can mutate both replicating and non-replicating DNA. In contrast, a base analog can mutate the DNA only when the analog is incorporated in replicating the DNA. Each of these classes of chemical mutagens has certain effects that then lead to transitions, transversions, or deletions.
- Agents that form DNA adducts (e.g., ochratoxin A metabolites)[26]
- DNA intercalating agents (e.g., ethidium bromide)
- DNA crosslinkers
- Oxidative damage
- Nitrous acid converts amine groups on A and C to diazo groups, altering their hydrogen bonding patterns, which leads to incorrect base pairing during replication.
- Radiation
- Ultraviolet radiation (nonionizing radiation). Two nucleotide bases in DNA — cytosine and thymine — are most vulnerable to radiation that can change their properties. UV light can induce adjacent pyrimidine bases in a DNA strand to become covalently joined as a pyrimidine dimer. UV radiation, in particular longer-wave UVA, can also cause oxidative damage to DNA.[27]
Classification of mutation types
By effect on structure

Illustrations of five types of chromosomal mutations.
The sequence of a gene can be altered in a number of ways. Gene mutations have varying effects on health depending on where they occur and whether they alter the function of essential proteins. Mutations in the structure of genes can be classified as:
- Small-scale mutations, such as those affecting a small gene in one or a few nucleotides, including:
- Point mutations, often caused by chemicals or malfunction of DNA replication, exchange a single nucleotide for another.[29] These changes are classified as transitions or transversions.[30] Most common is the transition that exchanges a purine for a purine (A ↔ G) or a pyrimidine for a pyrimidine, (C ↔ T). A transition can be caused by nitrous acid, base mis-pairing, or mutagenic base analogs such as 5-bromo-2-deoxyuridine (BrdU). Less common is a transversion, which exchanges a purine for a pyrimidine or a pyrimidine for a purine (C/T ↔ A/G). An example of a transversion is the conversion of adenine (A) into a cytosine (C). A point mutation can be reversed by another point mutation, in which the nucleotide is changed back to its original state (true reversion) or by second-site reversion (a complementary mutation elsewhere that results in regained gene functionality). Point mutations that occur within the protein coding region of a gene may be classified into three kinds, depending upon what the erroneous codon codes for:
- Insertions add one or more extra nucleotides into the DNA. They are usually caused by transposable elements, or errors during replication of repeating elements (e.g., AT repeats[citation needed]). Insertions in the coding region of a gene may alter splicing of the mRNA (splice site mutation), or cause a shift in the reading frame (frameshift), both of which can significantly alter the gene product. Insertions can be reversed by excision of the transposable element.
- Deletions remove one or more nucleotides from the DNA. Like insertions, these mutations can alter the reading frame of the gene. In general, they are irreversible: Though exactly the same sequence might in theory be restored by an insertion, transposable elements able to revert a very short deletion (say 1–2 bases) in any location either are highly unlikely to exist or do not exist at all.
- Large-scale mutations in chromosomal structure, including:
- Amplifications (or gene duplications) leading to multiple copies of all chromosomal regions, increasing the dosage of the genes located within them.
- Deletions of large chromosomal regions, leading to loss of the genes within those regions.
- Mutations whose effect is to juxtapose previously separate pieces of DNA, potentially bringing together separate genes to form functionally distinct fusion genes (e.g., bcr-abl). These include:
- Chromosomal translocations: interchange of genetic parts from nonhomologous chromosomes.
- Interstitial deletions: an intra-chromosomal deletion that removes a segment of DNA from a single chromosome, thereby apposing previously distant genes. For example, cells isolated from a human astrocytoma, a type of brain tumor, were found to have a chromosomal deletion removing sequences between the "fused in glioblastoma" (fig) gene and the receptor tyrosine kinase "ros", producing a fusion protein (FIG-ROS). The abnormal FIG-ROS fusion protein has constitutively active kinase activity that causes oncogenic transformation (a transformation from normal cells to cancer cells).
- Chromosomal inversions: reversing the orientation of a chromosomal segment.
- Loss of heterozygosity: loss of one allele, either by a deletion or a recombination event, in an organism that previously had two different alleles.
By effect on function
- Loss-of-function mutations result in the gene product having less or no function. When the allele has a complete loss of function (null allele) it is often called an amorphic mutation. Phenotypes associated with such mutations are most often recessive. Exceptions are when the organism is haploid, or when the reduced dosage of a normal gene product is not enough for a normal phenotype (this is called haploinsufficiency).
- Gain-of-function mutations change the gene product such that it gains a new and abnormal function. These mutations usually have dominant phenotypes. Often called a neomorphic mutation.
- Dominant negative mutations (also called antimorphic mutations) have an altered gene product that acts antagonistically to the wild-type allele. These mutations usually result in an altered molecular function (often inactive) and are characterized by a dominant or semi-dominant phenotype. In humans, dominant negative mutations have been implicated in cancer (e.g., mutations in genes p53,[31] ATM,[32] CEBPA[33] and PPARgamma[34]). It was once thought that Marfan syndrome is an example of a the occurrence of a dominant negative mutation in an autosomal-dominant disease where the defective glycoprotein product of the fibrillin gene (FBN1) antagonizes the product of the normal allele. However, it may appear this is not that case and that Marfan's may be a result of haploinsufficiency due to the absence of one normal allele that causes the disease not the presence of an abnormal allele (i.e., Dominant negative).[citation needed]
- Lethal mutations are mutations that lead to the death of the organisms that carry the mutations.
- A back mutation or reversion is a point mutation that restores the original sequence and hence the original phenotype.[35]
By effect on fitness
In applied genetics, it is usual to speak of mutations as either harmful or beneficial.
- A harmful, or deleterious, mutation decreases the fitness of the organism.
- A beneficial, or advantageous mutation increases the fitness of the organism. Mutations that promotes traits that are desirable, are also called beneficial. In theoretical population genetics, it is more usual to speak of mutations as deleterious or advantageous than harmful or beneficial.
- A neutral mutation has no harmful or beneficial effect on the organism. Such mutations occur at a steady rate, forming the basis for the molecular clock. In the neutral theory of molecular evolution, neutral mutations provide genetic drift is the basis for most variation at the molecular level.
- A nearly neutral mutation is a mutation that may be slightly deleterious or advantageous, although most nearly neutral mutations are slightly deleterious.
Distribution of SHIBA effects
In reality, viewing the fitness effects of mutations in these discrete categories is an oversimplification. Attempts have been made to infer the distribution of fitness effects (DFE) using
mutagenesis experiments and theoretical models applied to molecular sequence data. Distribution of fitness effects, as used to determine the relative abundance of different types of mutations (i.e., strongly deleterious, nearly neutral or advantageous), is relevant to many evolutionary questions, such as the maintenance of
genetic variation,
[36] the rate of genomic decay,
[37] the maintenance of outcrossing sexual reproduction as opposed to inbreeding
[38] and the evolution of sex and
recombination.
[39] In summary, DFE plays an important role in predicting
evolutionary dynamics.
[40][41] A variety of approaches have been used to study the distribution of fitness effects, including theoretical, experimental and analytical methods.
- Mutagenesis experiment: The direct method to investigate DFE is to induce mutations and then measure the mutational fitness effects, which has already been done in viruses, bacteria, yeast, and Drosophila. For example, most studies of DFE in viruses used site-directed mutagenesis to create point mutations and measure relative fitness of each mutant.[42][43][44][45] In Escherichia coli, one study used transposon mutagenesis to directly measure the fitness of a random insertion of a derivative of Tn10.[46] In yeast, a combined mutagenesis and deep sequencing approach has been developed to generate high-quality systematic mutant libraries and measure fitness in high throughput.[47] However, given that many mutations have effects too small to be detected[48] and that mutagenesis experiments can detect only mutations of moderately large effect; DNA sequence data analysis can provide valuable information about these mutations.
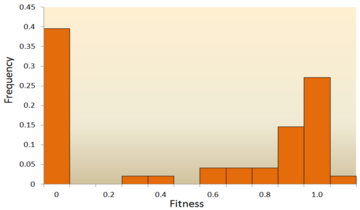
The distribution of fitness effects of mutations in vesicular stomatitis virus. In this experiment, random mutations were introduced into the virus by site-directed mutagenesis, and the fitness of each mutant was compared with the ancestral type. A fitness of zero, less than one, one, more than one, respectively, indicates that mutations are lethal, deleterious, neutral, and advantageous. Data from.
[42]
- Molecular sequence analysis: With rapid development of DNA sequencing technology, an enormous amount of DNA sequence data is available and even more is forthcoming in the future. Various methods have been developed to infer DFE from DNA sequence data.[49][50][51][52] By examining DNA sequence differences within and between species, we are able to infer various characteristics of the DFE for neutral, deleterious and advantageous mutations.[20] To be specific, the DNA sequence analysis approach allows us to estimate the effects of mutations with very small effects, which are hardly detectable through mutagenesis experiments.
One of the earliest theoretical studies of the distribution of fitness effects was done by
Motoo Kimura, an influential theoretical population geneticist. His
neutral theory of molecular evolution proposes that most novel mutations will be highly deleterious, with a small fraction being neutral.
[53][54] Hiroshi Akashi more recently proposed a
bimodal model for DFE, with modes centered around highly deleterious and neutral mutations.
[55] Both theories agree that the vast majority of novel mutations are neutral or deleterious and that advantageous mutations are rare, which has been supported by experimental results. One example is a study done on the distribution of fitness effects of random mutations in
vesicular stomatitis virus.
[42] Out of all mutations, 39.6% were lethal, 31.2% were non-lethal deleterious, and 27.1% were neutral. Another example comes from a high throughput mutagenesis experiment with yeast.
[47] In this experiment it was shown that the overall distribution of fitness effects is bimodal, with a cluster of neutral mutations, and a broad distribution of deleterious mutations.
Though relatively few mutations are advantageous, those that are play an important role in evolutionary changes.
[56] Like neutral mutations, weakly selected advantageous mutations can be lost due to
random genetic drift, but strongly selected advantageous mutations are more likely to be fixed. Knowing the distribution of fitness effects of advantageous mutations may lead to increased ability to predict the
evolutionary dynamics. Theoretical work on the DFE for advantageous mutations has been done by
John H. Gillespie[57] and
H. Allen Orr.
[58] They proposed that the distribution for advantageous mutations should be
exponential under a wide range of conditions, which, in general, has been supported by experimental studies, at least for strongly selected advantageous mutations.
[59][60][61]
In general, it is accepted that the majority of mutations are neutral or deleterious, with rare mutations being advantageous; however, the proportion of types of mutations varies between species. This indicates two important points: first, the proportion of effectively neutral mutations is likely to vary between species, resulting from dependence on
effective population size; second, the average effect of deleterious mutations varies dramatically between species.
[20] In addition, the DFE also differs between
coding regions and
non-coding regions, with the DFE of non-coding DNA containing more weakly selected mutations.
[20]
By impact on protein sequence
- A frameshift mutation is a mutation caused by insertion or deletion of a number of nucleotides that is not evenly divisible by three from a DNA sequence. Due to the triplet nature of gene expression by codons, the insertion or deletion can disrupt the reading frame, or the grouping of the codons, resulting in a completely different translation from the original.[62] The earlier in the sequence the deletion or insertion occurs, the more altered the protein produced is.
- In contrast, any insertion or deletion that is evenly divisible by three is termed an in-frame mutation
- A nonsense mutation is a point mutation in a sequence of DNA that results in a premature stop codon, or a nonsense codon in the transcribed mRNA, and possibly a truncated, and often nonfunctional protein product. (See Stop codon.)
- Missense mutations or nonsynonymous mutations are types of point mutations where a single nucleotide is changed to cause substitution of a different amino acid. This in turn can render the resulting protein nonfunctional. Such mutations are responsible for diseases such as Epidermolysis bullosa, sickle-cell disease, and SOD1 mediated ALS (Boillée 2006, p. 39).
- A neutral mutation is a mutation that occurs in an amino acid codon that results in the use of a different, but chemically similar, amino acid. The similarity between the two is enough that little or no change is often rendered in the protein. For example, a change from AAA to AGA will encode arginine, a chemically similar molecule to the intended lysine.
- Silent mutations are mutations that do not result in a change to the amino acid sequence of a protein, unless the changed amino acid is sufficiently similar to the original. They may occur in a region that does not code for a protein, or they may occur within a codon in a manner that does not alter the final amino acid sequence. The phrase silent mutation is often used interchangeably with the phrase synonymous mutation; however, synonymous mutations are a subcategory of the former, occurring only within exons (and necessarily exactly preserving the amino acid sequence of the protein). Synonymous mutations occur due to the degenerate nature of the genetic code. (See Genetic code.)
By inheritance

A mutation has caused this garden
moss rose to produce flowers of different colors. This is a somatic mutation that may also be passed on in the germ line.
In
multicellular organisms with dedicated
reproductive cells, mutations can be subdivided into
germ line mutations, which can be passed on to descendants through their reproductive cells, and
somatic mutations (also called acquired mutations),
[63] which involve cells outside the dedicated reproductive group and which are not usually transmitted to descendants.
A germline mutation gives rise to a
constitutional mutation in the offspring, that is, a mutation that is present in every cell. A constitutional mutation can also occur very soon after
fertilisation, or continue from a previous constitutional mutation in a parent.
[64]
The distinction between germline and somatic mutations is important in animals that have a dedicated germ line to produce reproductive cells. However, it is of little value in understanding the effects of mutations in plants, which lack dedicated germ line. The distinction is also blurred in those animals that reproduce
asexually through mechanisms such as
budding, because the cells that give rise to the daughter organisms also give rise to that organism´s germ line. A new mutation that was not inherited from either parent is called a
de novo mutation.
Diploid organisms (e.g., humans) contain two copies of each gene — a paternal and a maternal allele. Based on the occurrence of mutation on each chromosome, we may classify mutations into three types.
- A heterozygous mutation is a mutation of only one allele.
- A homozygous mutation is an identical mutation of both the paternal and maternal alleles.
- Compound heterozygous mutations or a genetic compound comprises two different mutations in the paternal and maternal alleles.[65]
A
wildtype or
homozygous non-mutated organism is one in which neither allele is mutated.
Special classes
- Conditional mutation is a mutation that has wild-type (or less severe) phenotype under certain "permissive" environmental conditions and a mutant phenotype under certain "restrictive" conditions. For example, a temperature-sensitive mutation can cause cell death at high temperature (restrictive condition), but might have no deleterious consequences at a lower temperature (permissive condition).
- Replication timing quantitative trait loci affects DNA replication.
Nomenclature
In order to categorize a mutation as such, the "normal" sequence must be obtained from the DNA of a "normal" or "healthy" organism (as opposed to a "mutant" or "sick" one), it should be identified and reported; ideally, it should be made publicly available for a straightforward nucleotide-by-nucleotide comparison, and agreed upon by the scientific community or by a group of expert geneticists and biologists, who have the responsibility of establishing the
standard or so-called "consensus" sequence. This step requires a tremendous scientific effort. (See
DNA sequencing.) Once the consensus sequence is known, the mutations in a genome can be pinpointed, described, and classified. The committee of the Human Genome Variation Society (HGVS) has developed the standard human sequence variant nomenclature,
[66] which should be used by researchers and
DNA diagnostic centers to generate unambiguous mutation descriptions. In principle, this nomenclature can also be used to describe mutations in other organisms. The nomenclature specifies the type of mutation and base or amino acid changes.
- Nucleotide substitution (e.g., 76A>T) — The number is the position of the nucleotide from the 5' end; the first letter represents the wild type nucleotide, and the second letter represents the nucleotide that replaced the wild type. In the given example, the adenine at the 76th position was replaced by a thymine.
- If it becomes necessary to differentiate between mutations in genomic DNA, mitochondrial DNA, and RNA, a simple convention is used. For example, if the 100th base of a nucleotide sequence mutated from G to C, then it would be written as g.100GC if the mutation occurred in mitochondrial DNA, or r.100g
- Amino acid substitution (e.g., D111E) — The first letter is the one letter code of the wild type amino acid, the number is the position of the amino acid from the N-terminus, and the second letter is the one letter code of the amino acid present in the mutation. Nonsense mutations are represented with an X for the second amino acid (e.g. D111X).
- Amino acid deletion (e.g., ΔF508) — The Greek letter Δ (delta) indicates a deletion. The letter refers to the amino acid present in the wild type and the number is the position from the N terminus of the amino acid were it to be present as in the wild type.
Contribution of mutations
The contribution of mutations is different in the tissues. This may be due to different mutation rates by cell division and the different number of cell divisions in each tissue.
Furthermore, knowing the mutational processes, mutation rates and the process of tissue development, can show the history of individual cells. For that, used cellular genome sequencing.
Mutation rates
Mutation rates vary across species. Evolutionary biologists
[citation needed] have theorized that higher mutation rates are beneficial in some situations, because they allow organisms to evolve and therefore adapt more quickly to their environments. For example, repeated exposure of bacteria to antibiotics, and selection of resistant mutants, can result in the selection of bacteria that have a much higher mutation rate than the original population (
mutator strains).
According to one study, two children of different parents had 35 and 49 new mutations. Of them, in one case 92% were from the paternal germline, in another case, 64% were from the maternal germline.
[67]
Harmful mutations
Changes in DNA caused by mutation can cause errors in
protein sequence, creating partially or completely non-functional proteins. Each cell, in order to function correctly, depends on thousands of proteins to function in the right places at the right times. When a mutation alters a protein that plays a critical role in the body, a medical condition can result. A condition caused by mutations in one or more genes is called a
genetic disorder. Some mutations alter a gene's DNA base sequence but do not change the function of the protein made by the gene. One study on the comparison of genes between different species of
Drosophila suggests that if a mutation does change a protein, this will probably be harmful, with an estimated 70 percent of amino acid polymorphisms having damaging effects, and the remainder being either neutral or weakly beneficial.
[4] Studies have shown that only 7% of point mutations in non-coding DNA of
yeast are deleterious and 12% in coding DNA are deleterious. The rest of the mutations are either neutral or slightly beneficial.
[68]
If a mutation is present in a
germ cell, it can give rise to offspring that carries the mutation in all of its cells. This is the case in
hereditary diseases. In particular, if there is a mutation in a DNA repair gene within a germ cell, humans carrying such germ-line mutations may have an increased risk of cancer. A list of 34 such germ-line mutations is given in the article
DNA repair-deficiency disorder. An example of one is albinism. A mutation that occurs in the OCA1 or OCA2 gene. Individuals with this disorder are more prone to many types of cancers, other disorders and have impaired vision. On the other hand, a mutation may occur in a
somatic cell of an organism. Such mutations will be present in all descendants of this cell within the same organism, and certain mutations can cause the cell to become malignant, and, thus, cause
cancer.
[69]
A DNA damage can cause an error when the DNA is replicated, and this error of replication can cause a gene mutation that, in turn, could cause a genetic disorder. DNA damages are repaired by the
DNA repair system of the cell. Each cell has a number of pathways through which enzymes recognize and repair damages in DNA. Because DNA can be damaged in many ways, the process of DNA repair is an important way in which the body protects itself from disease. Once a DNA damage has given rise to a mutation, the mutation cannot be repaired. DNA repair pathways can only recognize and act on "abnormal" structures in the DNA. Once a mutation occurs in a gene sequence it then has normal DNA structure and cannot be repaired.
Beneficial mutations
Although mutations that cause changes in protein sequences can be harmful to an organism, on occasions the effect may be positive in a given environment. In this case, the mutation may enable the mutant organism to withstand particular environmental stresses better than wild-type organisms, or reproduce more quickly. In these cases a mutation will tend to become more common in a population through
natural selection.
For example, a specific 32
base pair deletion in human
CCR5 (
CCR5-Δ32) confers
HIV resistance to
homozygotes and delays
AIDS onset in
heterozygotes.
[70] One possible explanation of the
etiology of the relatively high frequency of CCR5-Δ32 in the European population is that it conferred resistance to the
bubonic plague in mid-14th century Europe. People with this mutation were more likely to survive infection; thus its frequency in the population increased.
[71] This theory could explain why this mutation is not found in southern Africa, which remained untouched by bubonic plague. A newer theory suggests that the
selective pressure on the CCR5 Delta 32 mutation was caused by
smallpox instead of the bubonic plague.
[72]
Another example is
Sickle-cell disease, a blood disorder in which the body produces an abnormal type of the oxygen-carrying substance
hemoglobin in the
red blood cells. One-third of all
indigenous inhabitants of
Sub-Saharan Africa carry the gene,
[73][not in citation given] because, in areas where malaria is common, there is a
survival value in carrying only a single sickle-cell gene (
sickle-cell trait).
[74] Those with only one of the two
alleles of the sickle-cell disease are more resistant to malaria, since the infestation of the malaria plasmodium is halted by the sickling of the cells that it infests.
Prion mutations
Prions are proteins and do not contain genetic material. However, prion replication has been shown to be subject to mutation and
natural selection just like other forms of replication.
[75]
Somatic mutations
A change in the genetic structure that is not inherited from a parent, and also not passed to offspring, is called a
somatic cell genetic mutation or
acquired mutation.
[76]
When analyzing somatic mutations present in the cells of multicellular organisms, can know its origin and its past.
Cells with heterozygous mutations (one good copy of gene and one mutated copy) may function normally with the unmutated copy until the good copy has been spontaneously somatically mutated. This kind of mutation happens all the time in living organisms, but it is difficult to measure the rate. Measuring this rate is important in predicting the rate at which people may develop cancer.
[77]
Point mutations may arise from spontaneous mutations that occur during
DNA replication. The rate of mutation may be increased by
mutagens. Mutagens can be physical, such as radiation from
UV rays,
X-rays or extreme heat, or chemical (molecules that misplace base pairs or disrupt the helical shape of DNA). Mutagens associated with cancers are often studied to learn about cancer and its prevention.
Gain-of-function research
The aim of gain-of-function (GOF) research is to
genetically engineer increased transmissibility, virulence, or host range of pathogens. As such, it has been extremely controversial. As a
Nature editorial put it in October 2014, "revelations over the past few months of serious violations and accidents at some of the leading biosafety containment labs in the United States has burst the hubris that some scientists, and their institutions, have in their perceived ability to work safely with dangerous pathogens."
[78] There is a current moratorium on such work in the United States.










