Genetic diversity is the total number of genetic characteristics in the genetic makeup of a species. It is distinguished from genetic variability, which describes the tendency of genetic characteristics to vary.
Genetic diversity serves as a way for populations to adapt to
changing environments. With more variation, it is more likely that some
individuals in a population will possess variations of alleles
that are suited for the environment. Those individuals are more likely
to survive to produce offspring bearing that allele. The population will
continue for more generations because of the success of these
individuals.
The academic field of population genetics includes several hypotheses and theories regarding genetic diversity. The neutral theory of evolution proposes that diversity is the result of the accumulation of neutral substitutions. Diversifying selection
is the hypothesis that two subpopulations of a species live in
different environments that select for different alleles at a particular
locus. This may occur, for instance, if a species has a large range
relative to the mobility of individuals within it. Frequency-dependent selection is the hypothesis that as alleles become more common, they become more vulnerable. This occurs in host–pathogen interactions, where a high frequency of a defensive allele among the host means that it is more likely that a pathogen will spread if it is able to overcome that allele.
Within Species Diversity
Varieties of maize in the office of the Russian plant geneticist Nikolai Vavilov
A study conducted by the National Science Foundation in 2007 found that genetic diversity ( within species diversity) and biodiversity
are dependent upon each other — i.e. that diversity within a species
is necessary to maintain diversity among species, and vice versa.
According to the lead researcher in the study, Dr. Richard Lankau, "If
any one type is removed from the system, the cycle can break down, and
the community becomes dominated by a single species." Genotypic and phenotypic diversity have been found in all species at the protein, DNA, and organismal levels; in nature, this diversity is nonrandom, heavily structured, and correlated with environmental variation and stress.
The interdependence between genetic and species diversity is
delicate. Changes in species diversity lead to changes in the
environment, leading to adaptation of the remaining species. Changes in
genetic diversity, such as in loss of species, leads to a loss of
biological diversity. Loss of genetic diversity in domestic animal populations has also been studied and attributed to the extension of markets and economic globalization.
Evolutionary importance of Genetic Diversity
Adaptation
Variation in the populations gene pool allows natural selection
to act upon traits that allow the population to adapt to changing
environments. Selection for or against a trait can occur with changing
environment – resulting in an increase in genetic diversity (if a new
mutation is selected for and maintained) or a decrease in genetic
diversity (if a disadvantageous allele is selected against). Hence, genetic diversity plays an important role in the survival and adaptability of a species.
The capability of the population to adapt to the changing environment
will depend on the presence of the necessary genetic diversity
The more genetic diversity a population has, the more likelihood the
population will be able to adapt and survive. Conversely, the
vulnerability of a population to changes, such as climate change or
novel diseases will increase with reduction in genetic diversity.
For example, the inability of koalas to adapt to fight Chlamydia and
the koala retrovirus (KoRV) has been linked to the koala’s low genetic
diversity.
This low genetic diversity also has geneticists concerned for the
koalas ability to adapt to climate change and human-induced
environmental changes in the future.
Small populations
Large populations are more likely to maintain genetic material and thus generally have higher genetic diversity. Small populations are more likely to experience the loss of diversity over time by random chance, which is called genetic drift. When an allele (variant of a gene) drifts to fixation, the other allele at the same locus is lost, resulting in a loss in genetic diversity.
In small population sizes, inbreeding, or mating between individuals
with similar genetic makeup, is more likely to occur, thus perpetuating
more common alleles to the point of fixation, thus decreasing genetic
diversity.
Concerns about genetic diversity are therefore especially important
with large mammals due to their small population size and high levels of
human-caused population effects.
A genetic bottleneck
can occur when a population goes through a period of low number of
individuals, resulting in a rapid decrease in genetic diversity. Even
with an increase in population size, the genetic diversity often
continues to be low if the entire species began with a small population,
since beneficial mutations (see below) are rare, and the gene pool is
limited by the small starting population. This is an important consideration in the area of conservation genetics, when working toward a rescued population or species that is genetically-healthy.
Mutation
Random mutations consistently generate genetic variation.
A mutation will increase genetic diversity in the short term, as a new
gene is introduced to the gene pool. However, the persistence of this
gene is dependent of drift and selection (see above). Most new mutations
either have a neutral or negative effect on fitness, while some have a
positive effect.
A beneficial mutation is more likely to persist and thus have a
long-term positive effect on genetic diversity. Mutation rates differ
across the genome, and larger populations have greater mutation rates. In smaller populations a mutation is less likely to persist because it is more likely to be eliminated by drift.
Gene Flow
Gene flow,
often by migration, is the movement of genetic material (for example by
pollen in the wind, or the migration of a bird). Gene flow can
introduce novel alleles to a population. These alleles can be integrated
into the population, thus increasing genetic diversity.
For example, an insecticide-resistant mutation arose in Anopheles gambiae African mosquitoes. Migration of some A. gambiae mosquitoes to a population of Anopheles coluzziin
mosquitoes resulted in a transfer of the beneficial resistance gene
from one species to the other. The genetic diversity was increased in A. gambiae by mutation and in A. coluzziin by gene flow.
In agriculture
In crops
When humans initially started farming, they used selective breeding to pass on desirable traits of the crops while omitting the undesirable ones. Selective breeding leads to monocultures:
entire farms of nearly genetically identical plants. Little to no
genetic diversity makes crops extremely susceptible to widespread
disease; bacteria morph and change constantly and when a disease-causing
bacterium changes to attack a specific genetic variation, it can easily
wipe out vast quantities of the species. If the genetic variation that
the bacterium is best at attacking happens to be that which humans have
selectively bred to use for harvest, the entire crop will be wiped out.
The nineteenth-century Potato Famine
in Ireland was in part caused by lack of biodiversity. Since new potato
plants do not come as a result of reproduction, but rather from pieces
of the parent plant, no genetic diversity is developed, and the entire
crop is essentially a clone of one potato, it is especially susceptible
to an epidemic. In the 1840s, much of Ireland's population depended on
potatoes for food. They planted namely the "lumper" variety of potato,
which was susceptible to a rot-causing oomycete called Phytophthora infestans. The fungus destroyed the vast majority of the potato crop, and left one million people to starve to death.
Genetic diversity in agriculture does not only relate to disease,
but also herbivores. Similarly, to the above example, monoculture
agriculture selects for traits that are uniform throughout the plot. If
this genotype is susceptible to certain herbivores, this could result in the loss of a large portion of the crop. One way farmers get around this is through inter-cropping.
By planting rows of unrelated, or genetically distinct crops as
barriers between herbivores and their preferred host plant, the farmer
effectively reduces the ability of the herbivore to spread throughout
the entire plot.
In livestock
The genetic diversity of livestock species permits animal husbandry in a range of environments and with a range of different objectives. It provides the raw material for selective breeding programmes and allows livestock populations to adapt as environmental conditions change.
Livestock biodiversity can be lost as a result of breed extinctions and other forms of genetic erosion. As of June 2014, among the 8,774 breeds recorded in the Domestic Animal Diversity Information System (DAD-IS), operated by the Food and Agriculture Organization of the United Nations (FAO), 17 percent were classified as being at risk of extinction and 7 percent already extinct.
There is now a Global Plan of Action for Animal Genetic Resources that
was developed under the auspices of the Commission on Genetic Resources
for Food and Agriculture in 2007, that provides a framework and
guidelines for the management of animal genetic resources.
Awareness of the importance of maintaining animal genetic resources has increased over time. FAO has published two reports on the state of the world's animal genetic resources for food and agriculture, which cover detailed analyses of our global livestock diversity and ability to manage and conserve them.
Viral Implications
High
genetic diversity in viruses must be considered when designing
vaccinations. High genetic diversity results in difficulty in designing
targeted vaccines, and allows for viruses to quickly evolve to resist
vaccination lethality. For example, malaria vaccinations are impacted by
high levels of genetic diversity in the protein antigens. In addition, HIV-1 genetic diversity limits the use of currently available viral load and resistance tests.
The natural world has several ways of preserving or increasing genetic diversity. Among oceanic plankton, viruses
aid in the genetic shifting process. Ocean viruses, which infect the
plankton, carry genes of other organisms in addition to their own. When a
virus containing the genes of one cell infects another, the genetic
makeup of the latter changes. This constant shift of genetic makeup
helps to maintain a healthy population of plankton despite complex and
unpredictable environmental changes.
Cheetahs are a threatened species.
Low genetic diversity and resulting poor sperm quality has made
breeding and survivorship difficult for cheetahs. Moreover, only about
5% of cheetahs survive to adulthood
However, it has been recently discovered that female cheetahs can mate
with more than one male per litter of cubs. They undergo induced
ovulation, which means that a new egg is produced every time a female
mates. By mating with multiple males, the mother increases the genetic
diversity within a single litter of cubs.
Human Intervention
Attempts
to increase the viability of a species by increasing genetic diversity
is called genetic rescue. For example, eight panthers from Texas were
introduced to the Florida panther population, which was declining and
suffering from inbreeding depression. Genetic variation was thus
increased and resulted in a significant increase in population growth of
the Florida Panther.
Creating or maintaining high genetic diversity is an important
consideration in species rescue efforts, in order to ensure the
longevity of a population.
Measures
Genetic diversity of a population can be assessed by some simple measures.
Gene diversity is the proportion of polymorphic loci across the genome.
Heterozygosity is the fraction of individuals in a population that are heterozygous for a particular locus.
Alleles per locus is also used to demonstrate variability.
Nucleotide diversity
is the extent of nucleotide polymorphisms within a population, and is
commonly measured through molecular markers such as micro- and
minisatellite sequences, mitochondrial DNA, and single-nucleotide polymorphisms (SNPs).
Furthermore, stochastic simulation software is commonly used to
predict the future of a population given measures such as allele
frequency and population size.
Metagenomics
allows the study of microbial communities like those present in this
stream receiving acid drainage from surface coal mining.
Metagenomics is the study of genetic material recovered directly from environmental samples. The broad field may also be referred to as environmental genomics, ecogenomics or community genomics.
While traditional microbiology and microbial genome sequencing and genomics rely upon cultivated clonalcultures, early environmental gene sequencing cloned specific genes (often the 16S rRNA gene) to produce a profile of diversity in a natural sample. Such work revealed that the vast majority of microbial biodiversity had been missed by cultivation-based methods.
Because of its ability to reveal the previously hidden diversity
of microscopic life, metagenomics offers a powerful lens for viewing the
microbial world that has the potential to revolutionize understanding
of the entire living world. As the price of DNA sequencing continues to fall, metagenomics now allows microbial ecology to be investigated at a much greater scale and detail than before. Recent studies use either "shotgun" or PCR directed sequencing to get largely unbiased samples of all genes from all the members of the sampled communities.
Etymology
The term "metagenomics" was first used by Jo Handelsman, Jon Clardy, Robert M. Goodman, Sean F. Brady, and others, and first appeared in publication in 1998.
The term metagenome referenced the idea that a collection of genes
sequenced from the environment could be analyzed in a way analogous to
the study of a single genome. In 2005, Kevin Chen and Lior Pachter (researchers at the University of California, Berkeley)
defined metagenomics as "the application of modern genomics technique
without the need for isolation and lab cultivation of individual
species".
History
Conventional sequencing begins with a culture of identical cells as a source of DNA.
However, early metagenomic studies revealed that there are probably
large groups of microorganisms in many environments that cannot be cultured and thus cannot be sequenced. These early studies focused on 16S ribosomalRNA sequences which are relatively short, often conserved within a species, and generally different between species. Many 16S rRNA sequences have been found which do not belong to any known cultured species,
indicating that there are numerous non-isolated organisms. These
surveys of ribosomal RNA (rRNA) genes taken directly from the
environment revealed that cultivation based methods find less than 1% of the bacterial and archaeal species in a sample.
Much of the interest in metagenomics comes from these discoveries that
showed that the vast majority of microorganisms had previously gone
unnoticed.
Early molecular work in the field was conducted by Norman R. Pace and colleagues, who used PCR to explore the diversity of ribosomal RNA sequences.
The insights gained from these breakthrough studies led Pace to propose
the idea of cloning DNA directly from environmental samples as early as
1985. This led to the first report of isolating and cloning bulk DNA from an environmental sample, published by Pace and colleagues in 1991 while Pace was in the Department of Biology at Indiana University. Considerable efforts ensured that these were not PCR
false positives and supported the existence of a complex community of
unexplored species. Although this methodology was limited to exploring
highly conserved, non-protein coding genes,
it did support early microbial morphology-based observations that
diversity was far more complex than was known by culturing methods. Soon
after that, Healy reported the metagenomic isolation of functional
genes from "zoolibraries" constructed from a complex culture of
environmental organisms grown in the laboratory on dried grasses in 1995. After leaving the Pace laboratory, Edward DeLong
continued in the field and has published work that has largely laid the
groundwork for environmental phylogenies based on signature 16S
sequences, beginning with his group's construction of libraries from marine samples.
In 2002, Mya Breitbart, Forest Rohwer,
and colleagues used environmental shotgun sequencing (see below) to
show that 200 liters of seawater contains over 5000 different viruses. Subsequent studies showed that there are more than a thousand viral species in human stool and possibly a million different viruses per kilogram of marine sediment, including many bacteriophages. Essentially all of the viruses in these studies were new species. In 2004, Gene Tyson, Jill Banfield, and colleagues at the University of California, Berkeley and the Joint Genome Institute sequenced DNA extracted from an acid mine drainage system. This effort resulted in the complete, or nearly complete, genomes for a handful of bacteria and archaea that had previously resisted attempts to culture them.
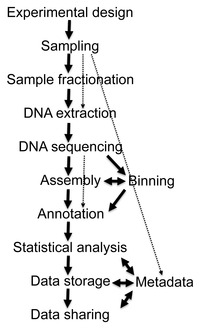
Flow diagram of a typical metagenome project
Beginning in 2003, Craig Venter, leader of the privately funded parallel of the Human Genome Project, has led the Global Ocean Sampling Expedition
(GOS), circumnavigating the globe and collecting metagenomic samples
throughout the journey. All of these samples are sequenced using shotgun
sequencing, in hopes that new genomes (and therefore new organisms)
would be identified. The pilot project, conducted in the Sargasso Sea, found DNA from nearly 2000 different species, including 148 types of bacteria never before seen. Venter has circumnavigated the globe and thoroughly explored the West Coast of the United States, and completed a two-year expedition to explore the Baltic, Mediterranean and Black
Seas. Analysis of the metagenomic data collected during this journey
revealed two groups of organisms, one composed of taxa adapted to
environmental conditions of 'feast or famine', and a second composed of
relatively fewer but more abundantly and widely distributed taxa
primarily composed of plankton.
Environmental
Shotgun Sequencing (ESS). (A) Sampling from habitat; (B) filtering
particles, typically by size; (C) Lysis and DNA extraction; (D) cloning
and library construction; (E) sequencing the clones; (F) sequence
assembly into contigs and scaffolds.
Shotgun metagenomics
Advances in bioinformatics,
refinements of DNA amplification, and the proliferation of
computational power have greatly aided the analysis of DNA sequences
recovered from environmental samples, allowing the adaptation of shotgun sequencing
to metagenomic samples (known also as whole metagenome shotgun or WMGS
sequencing). The approach, used to sequence many cultured microorganisms
and the human genome, randomly shears DNA, sequences many short sequences, and reconstructs them into a consensus sequence.
Shotgun sequencing reveals genes present in environmental samples.
Historically, clone libraries were used to facilitate this sequencing.
However, with advances in high throughput sequencing technologies, the
cloning step is no longer necessary and greater yields of sequencing
data can be obtained without this labour-intensive bottleneck step.
Shotgun metagenomics provides information both about which organisms are
present and what metabolic processes are possible in the community.
Because the collection of DNA from an environment is largely
uncontrolled, the most abundant organisms in an environmental sample are
most highly represented in the resulting sequence data. To achieve the
high coverage needed to fully resolve the genomes of under-represented
community members, large samples, often prohibitively so, are needed. On
the other hand, the random nature of shotgun sequencing ensures that
many of these organisms, which would otherwise go unnoticed using
traditional culturing techniques, will be represented by at least some
small sequence segments. An emerging approach combines shotgun sequencing and chromosome conformation capture (Hi-C), which measures the proximity of any two DNA sequences within the same cell, to guide microbial genome assembly.
High-throughput sequencing
The first metagenomic studies conducted using high-throughput sequencing used massively parallel 454 pyrosequencing. Three other technologies commonly applied to environmental sampling are the Ion Torrent Personal Genome Machine, the Illumina MiSeq or HiSeq and the Applied Biosystems SOLiD system. These techniques for sequencing DNA generate shorter fragments than Sanger sequencing;
Ion Torrent PGM System and 454 pyrosequencing typically produces
~400 bp reads, Illumina MiSeq produces 400-700bp reads (depending on
whether paired end options are used), and SOLiD produce 25-75 bp reads.
Historically, these read lengths were significantly shorter than the
typical Sanger sequencing read length of ~750 bp, however the Illumina
technology is quickly coming close to this benchmark. However, this
limitation is compensated for by the much larger number of sequence
reads. In 2009, pyrosequenced metagenomes generate 200–500 megabases,
and Illumina platforms generate around 20–50 gigabases, but these
outputs have increased by orders of magnitude in recent years.
An additional advantage to high throughput sequencing is that this
technique does not require cloning the DNA before sequencing, removing
one of the main biases and bottlenecks in environmental sampling.
Bioinformatics
The
data generated by metagenomics experiments are both enormous and
inherently noisy, containing fragmented data representing as many as
10,000 species. The sequencing of the cow rumen metagenome generated 279 gigabases, or 279 billion base pairs of nucleotide sequence data, while the human gut microbiome gene catalog identified 3.3 million genes assembled from 567.7 gigabases of sequence data.
Collecting, curating, and extracting useful biological information from
datasets of this size represent significant computational challenges
for researchers.
Sequence pre-filtering
The
first step of metagenomic data analysis requires the execution of
certain pre-filtering steps, including the removal of redundant,
low-quality sequences and sequences of probable eukaryotic origin (especially in metagenomes of human origin). The methods available for the removal of contaminating eukaryotic genomic DNA sequences include Eu-Detect and DeConseq.
Assembly
DNA sequence data from genomic and metagenomic projects are essentially the same, but genomic sequence data offers higher coverage while metagenomic data is usually highly non-redundant.
Furthermore, the increased use of second-generation sequencing
technologies with short read lengths means that much of future
metagenomic data will be error-prone. Taken in combination, these
factors make the assembly of metagenomic sequence reads into genomes
difficult and unreliable. Misassemblies are caused by the presence of repetitive DNA sequences that make assembly especially difficult because of the difference in the relative abundance of species present in the sample. Misassemblies can also involve the combination of sequences from more than one species into chimeric contigs.
There are several assembly programs, most of which can use information from paired-end tags in order to improve the accuracy of assemblies. Some programs, such as Phrap or Celera Assembler, were designed to be used to assemble single genomes but nevertheless produce good results when assembling metagenomic data sets. Other programs, such as Velvet assembler, have been optimized for the shorter reads produced by second-generation sequencing through the use of de Bruijn graphs.
The use of reference genomes allows researchers to improve the assembly
of the most abundant microbial species, but this approach is limited by
the small subset of microbial phyla for which sequenced genomes are
available.
After an assembly is created, an additional challenge is "metagenomic
deconvolution", or determining which sequences come from which species
in the sample.
Gene prediction
Metagenomic analysis pipelines use two approaches in the annotation of coding regions in the assembled contigs. The first approach is to identify genes based upon homology with genes that are already publicly available in sequence databases, usually by BLAST searches. This type of approach is implemented in the program MEGAN4. The second, ab initio,
uses intrinsic features of the sequence to predict coding regions based
upon gene training sets from related organisms. This is the approach
taken by programs such as GeneMark and GLIMMER. The main advantage of ab initio
prediction is that it enables the detection of coding regions that lack
homologs in the sequence databases; however, it is most accurate when
there are large regions of contiguous genomic DNA available for
comparison.
Gene annotations provide the "what", while measurements of species diversity provide the "who". In order to connect community composition and function in metagenomes, sequences must be binned. Binning is the process of associating a particular sequence with an organism. In similarity-based binning, methods such as BLAST
are used to rapidly search for phylogenetic markers or otherwise
similar sequences in existing public databases. This approach is
implemented in MEGAN. Another tool, PhymmBL, uses interpolated Markov models to assign reads. MetaPhlAn and AMPHORA
are methods based on unique clade-specific markers for estimating
organismal relative abundances with improved computational performances. Other tools, like mOTUs and MetaPhyler, use universal marker genes to profile prokaryotic species. With the mOTUs profiler is possible to profile species without a reference genome, improving the estimation of microbial community diversity. Recent methods, such as SLIMM,
use read coverage landscape of individual reference genomes to minimize
false-positive hits and get reliable relative abundances. In composition based binning, methods use intrinsic features of the sequence, such as oligonucleotide frequencies or codon usage bias. Once sequences are binned, it is possible to carry out comparative analysis of diversity and richness.
Data integration
The massive amount of exponentially growing sequence data is a daunting challenge that is complicated by the complexity of the metadata
associated with metagenomic projects. Metadata includes detailed
information about the three-dimensional (including depth, or height)
geography and environmental features of the sample, physical data about
the sample site, and the methodology of the sampling. This information is necessary both to ensure replicability
and to enable downstream analysis. Because of its importance, metadata
and collaborative data review and curation require standardized data
formats located in specialized databases, such as the Genomes OnLine
Database (GOLD).
Several tools have been developed to integrate metadata and
sequence data, allowing downstream comparative analyses of different
datasets using a number of ecological indices. In 2007, Folker Meyer and
Robert Edwards and a team at Argonne National Laboratory and the University of Chicago released the Metagenomics Rapid Annotation using Subsystem Technology server (MG-RAST) a community resource for metagenome data set analysis. As of June 2012 over 14.8 terabases (14x1012
bases) of DNA have been analyzed, with more than 10,000 public data
sets freely available for comparison within MG-RAST. Over 8,000 users
now have submitted a total of 50,000 metagenomes to MG-RAST. The Integrated Microbial Genomes/Metagenomes
(IMG/M) system also provides a collection of tools for functional
analysis of microbial communities based on their metagenome sequence,
based upon reference isolate genomes included from the Integrated Microbial Genomes (IMG) system and the Genomic Encyclopedia of Bacteria and Archaea (GEBA) project.
One of the first standalone tools for analysing high-throughput metagenome shotgun data was MEGAN (MEta Genome ANalyzer).
A first version of the program was used in 2005 to analyse the
metagenomic context of DNA sequences obtained from a mammoth bone.
Based on a BLAST comparison against a reference database, this tool
performs both taxonomic and functional binning, by placing the reads
onto the nodes of the NCBI taxonomy using a simple lowest common
ancestor (LCA) algorithm or onto the nodes of the SEED or KEGG classifications, respectively.
With the advent of fast and inexpensive sequencing instruments,
the growth of databases of DNA sequences is now exponential (e.g., the
NCBI GenBank database).
Faster and efficient tools are needed to keep pace with the
high-throughput sequencing, because the BLAST-based approaches such as
MG-RAST or MEGAN run slowly to annotate large samples (e.g., several
hours to process a small/medium size dataset/sample).
Thus, ultra-fast classifiers have recently emerged, thanks to more
affordable powerful servers. These tools can perform the taxonomic
annotation at extremely high speed, for example CLARK (according to CLARK's authors, it can classify accurately "32 million
metagenomic short reads per minute"). At such a speed, a very large
dataset/sample of a billion short reads can be processed in about 30
minutes.
With the increasing availability of samples containing ancient
DNA and due to the uncertainty associated with the nature of those
samples (ancient DNA damage), FALCON,
a fast tool capable of producing conservative similarity estimates has
been made available. According to FALCON's authors, it can use relaxed
thresholds and edit distances without affecting the memory and speed
performance.
Comparative metagenomics
Comparative
analyses between metagenomes can provide additional insight into the
function of complex microbial communities and their role in host health. Pairwise or multiple comparisons between metagenomes can be made at the level of sequence composition (comparing GC-content
or genome size), taxonomic diversity, or functional complement.
Comparisons of population structure and phylogenetic diversity can be
made on the basis of 16S and other phylogenetic marker genes, or—in the
case of low-diversity communities—by genome reconstruction from the
metagenomic dataset. Functional comparisons between metagenomes may be made by comparing sequences against reference databases such as COG or KEGG, and tabulating the abundance by category and evaluating any differences for statistical significance. This gene-centric approach emphasizes the functional complement of the community
as a whole rather than taxonomic groups, and shows that the functional
complements are analogous under similar environmental conditions.
Consequently, metadata on the environmental context of the metagenomic
sample is especially important in comparative analyses, as it provides
researchers with the ability to study the effect of habitat upon
community structure and function.
Additionally, several studies have also utilized oligonucleotide
usage patterns to identify the differences across diverse microbial
communities. Examples of such methodologies include the dinucleotide
relative abundance approach by Willner et al. and the HabiSign approach of Ghosh et al.
This latter study also indicated that differences in tetranucleotide
usage patterns can be used to identify genes (or metagenomic reads)
originating from specific habitats. Additionally some methods as
TriageTools or Compareads detect similar reads between two read sets. The similarity measure they apply on reads is based on a number of identical words of length k shared by pairs of reads.
A key goal in comparative metagenomics is to identify microbial
group(s) which are responsible for conferring specific characteristics
to a given environment. However, due to issues in the sequencing
technologies artifacts need to be accounted for like in metagenomeSeq. Others have characterized inter-microbial interactions between the resident microbial groups. A GUI-based comparative metagenomic analysis application called Community-Analyzer has been developed by Kuntal et al.
which implements a correlation-based graph layout algorithm that not
only facilitates a quick visualization of the differences in the
analyzed microbial communities (in terms of their taxonomic
composition), but also provides insights into the inherent
inter-microbial interactions occurring therein. Notably, this layout
algorithm also enables grouping of the metagenomes based on the probable
inter-microbial interaction patterns rather than simply comparing
abundance values of various taxonomic groups. In addition, the tool
implements several interactive GUI-based functionalities that enable
users to perform standard comparative analyses across microbiomes.
Data analysis
Community metabolism
In many bacterial communities, natural or engineered (such as bioreactors), there is significant division of labor in metabolism (Syntrophy), during which the waste products of some organisms are metabolites for others. In one such system, the methanogenic bioreactor, functional stability requires the presence of several syntrophic species (Syntrophobacterales and Synergistia) working together in order to turn raw resources into fully metabolized waste (methane). Using comparative gene studies and expression experiments with microarrays or proteomics
researchers can piece together a metabolic network that goes beyond
species boundaries. Such studies require detailed knowledge about which
versions of which proteins are coded by which species and even by which
strains of which species. Therefore, community genomic information is
another fundamental tool (with metabolomics and proteomics) in the quest to determine how metabolites are transferred and transformed by a community.
Metatranscriptomics
Metagenomics allows researchers to access the functional and
metabolic diversity of microbial communities, but it cannot show which
of these processes are active. The extraction and analysis of metagenomic mRNA (the metatranscriptome) provides information on the regulation and expression profiles of complex communities. Because of the technical difficulties (the short half-life of mRNA, for example) in the collection of environmental RNA there have been relatively few in situ metatranscriptomic studies of microbial communities to date. While originally limited to microarray technology, metatranscriptomics studies have made use of transcriptomics technologies to measure whole-genome expression and quantification of a microbial community, first employed in analysis of ammonia oxidation in soils.
Viruses
Metagenomic sequencing is particularly useful in the study of viral
communities. As viruses lack a shared universal phylogenetic marker (as 16S RNA for bacteria and archaea, and 18S RNA
for eukarya), the only way to access the genetic diversity of the viral
community from an environmental sample is through metagenomics. Viral
metagenomes (also called viromes) should thus provide more and more
information about viral diversity and evolution. For example, a metagenomic pipeline called Giant Virus Finder showed the first evidence of existence of giant viruses in a saline desert and in Antarctic dry valleys
.
The soils in which plants grow are inhabited by microbial communities, with one gram of soil containing around 109-1010 microbial cells which comprise about one gigabase of sequence information.
The microbial communities which inhabit soils are some of the most
complex known to science, and remain poorly understood despite their
economic importance. Microbial consortia perform a wide variety of ecosystem services necessary for plant growth, including fixing atmospheric nitrogen, nutrient cycling, disease suppression, and sequesteriron and other metals.
Functional metagenomics strategies are being used to explore the
interactions between plants and microbes through cultivation-independent
study of these microbial communities.
By allowing insights into the role of previously uncultivated or rare
community members in nutrient cycling and the promotion of plant growth,
metagenomic approaches can contribute to improved disease detection in crops and livestock and the adaptation of enhanced farming practices which improve crop health by harnessing the relationship between microbes and plants.
The efficient industrial-scale deconstruction of biomass requires novel enzymes with higher productivity and lower cost. Metagenomic approaches to the analysis of complex microbial communities allow the targeted screening of enzymes with industrial applications in biofuel production, such as glycoside hydrolases.
Furthermore, knowledge of how these microbial communities function is
required to control them, and metagenomics is a key tool in their
understanding. Metagenomic approaches allow comparative analyses between
convergent microbial systems like biogas fermenters or insectherbivores such as the fungus garden of the leafcutter ants.
Biotechnology
Microbial communities produce a vast array of biologically active chemicals that are used in competition and communication.
Many of the drugs in use today were originally uncovered in microbes;
recent progress in mining the rich genetic resource of non-culturable
microbes has led to the discovery of new genes, enzymes, and natural
products. The application of metagenomics has allowed the development of commodity and fine chemicals, agrochemicals and pharmaceuticals where the benefit of enzyme-catalyzedchiral synthesis is increasingly recognized.
Two types of analysis are used in the bioprospecting
of metagenomic data: function-driven screening for an expressed trait,
and sequence-driven screening for DNA sequences of interest.
Function-driven analysis seeks to identify clones expressing a desired
trait or useful activity, followed by biochemical characterization and
sequence analysis. This approach is limited by availability of a
suitable screen and the requirement that the desired trait be expressed
in the host cell. Moreover, the low rate of discovery (less than one per
1,000 clones screened) and its labor-intensive nature further limit
this approach. In contrast, sequence-driven analysis uses conserved DNA sequences to design PCR primers to screen clones for the sequence of interest.
In comparison to cloning-based approaches, using a sequence-only
approach further reduces the amount of bench work required. The
application of massively parallel sequencing also greatly increases the
amount of sequence data generated, which require high-throughput
bioinformatic analysis pipelines.
The sequence-driven approach to screening is limited by the breadth and
accuracy of gene functions present in public sequence databases. In
practice, experiments make use of a combination of both functional and
sequence-based approaches based upon the function of interest, the
complexity of the sample to be screened, and other factors. An example of success using metagenomics as a biotechnology for drug discovery is illustrated with the malacidin antibiotics.
Ecology
Metagenomics can provide valuable insights into the functional ecology of environmental communities.
Metagenomic analysis of the bacterial consortia found in the
defecations of Australian sea lions suggests that nutrient-rich sea lion
faeces may be an important nutrient source for coastal ecosystems. This
is because the bacteria that are expelled simultaneously with the
defecations are adept at breaking down the nutrients in the faeces into a
bioavailable form that can be taken up into the food chain.
DNA sequencing can also be used more broadly to identify species present in a body of water, debris filtered from the air, or sample of dirt. This can establish the range of invasive species and endangered species, and track seasonal populations.
Environmental remediation
Metagenomics can improve strategies for monitoring the impact of pollutants on ecosystems
and for cleaning up contaminated environments. Increased understanding
of how microbial communities cope with pollutants improves assessments
of the potential of contaminated sites to recover from pollution and
increases the chances of bioaugmentation or biostimulation trials to succeed.
Gut Microbe Characterization
Microbial communities play a key role in preserving human health, but their composition and the mechanism by which they do so remains mysterious.
Metagenomic sequencing is being used to characterize the microbial
communities from 15-18 body sites from at least 250 individuals. This is
part of the Human Microbiome initiative with primary goals to determine if there is a core human microbiome,
to understand the changes in the human microbiome that can be
correlated with human health, and to develop new technological and bioinformatics tools to support these goals.
Another medical study as part of the MetaHit (Metagenomics of the
Human Intestinal Tract) project consisted of 124 individuals from
Denmark and Spain consisting of healthy, overweight, and irritable bowel
disease patients. The study attempted to categorize the depth and
phylogenetic diversity of gastrointestinal bacteria. Using Illumina GA
sequence data and SOAPdenovo, a de Bruijn graph-based tool specifically
designed for assembly short reads, they were able to generate 6.58
million contigs greater than 500 bp for a total contig length of 10.3 Gb
and a N50 length of 2.2 kb.
The study demonstrated that two bacterial divisions,
Bacteroidetes and Firmicutes, constitute over 90% of the known
phylogenetic categories that dominate distal gut bacteria. Using the
relative gene frequencies found within the gut these researchers
identified 1,244 metagenomic clusters that are critically important for
the health of the intestinal tract. There are two types of functions in
these range clusters: housekeeping and those specific to the intestine.
The housekeeping gene clusters are required in all bacteria and are
often major players in the main metabolic pathways including central
carbon metabolism and amino acid synthesis. The gut-specific functions
include adhesion to host proteins and the harvesting of sugars from
globoseries glycolipids. Patients with irritable bowel syndrome were
shown to exhibit 25% fewer genes and lower bacterial diversity than
individuals not suffering from irritable bowel syndrome indicating that
changes in patients’ gut biome diversity may be associated with this
condition.
While these studies highlight some potentially valuable medical
applications, only 31-48.8% of the reads could be aligned to 194 public
human gut bacterial genomes and 7.6-21.2% to bacterial genomes available
in GenBank which indicates that there is still far more research
necessary to capture novel bacterial genomes.
Infectious disease diagnosis
Differentiating
between infectious and non-infectious illness, and identifying the
underlying etiology of infection, can be quite challenging. For example,
more than half of cases of encephalitis
remain undiagnosed, despite extensive testing using state-of-the-art
clinical laboratory methods. Metagenomic sequencing shows promise as a
sensitive and rapid method to diagnose infection by comparing genetic
material found in a patient's sample to a database of thousands of
bacteria, viruses, and other pathogens
Third-generation sequencing (also known as long-read sequencing) is a class of DNA sequencing methods currently under active development.
Third generation sequencing works by reading the nucleotide sequences
at the single molecule level, in contrast to existing methods that
require breaking long strands of DNA into small segments then inferring
nucleotide sequences by amplification and synthesis.
Critical challenges exist in the engineering of the necessary molecular
instruments for whole genome sequencing to make the technology
commercially available.
Second-generation sequencing,
often referred to as Next-generation sequencing (NGS), has dominated
the DNA sequencing space since its development. It has dramatically
reduced the cost of DNA sequencing by enabling a massively-paralleled
approach capable of producing large numbers of reads at exceptionally
high coverages throughout the genome.
Since eukaryotic genomes contain many repetitive regions, a major
limitation to this class of sequencing methods is the length of reads
it produces.
Briefly, second generation sequencing works by first amplifying the DNA
molecule and then conducting sequencing by synthesis. The collective
fluorescent signal resulting from synthesizing a large number of
amplified identical DNA strands allows the inference of nucleotide
identity. However, due to random errors, DNA synthesis between the
amplified DNA strands would become progressively out-of-sync. Quickly,
the signal quality deteriorates as the read-length grows. In order to
preserve read quality, long DNA molecules must be broken up into small
segments, resulting in a critical limitation of second generation
sequencing technologies. Computational efforts aimed to overcome this challenge often rely on approximative heuristics that may not result in accurate assemblies.
By enabling direct sequencing of single DNA molecules, third
generation sequencing technologies have the capability to produce
substantially longer reads than second generation sequencing.
Such an advantage has critical implications for both genome science and
the study of biology in general. However, third generation sequencing
data have much higher error rates than previous technologies, which can
complicate downstream genome assembly and analysis of the resulting
data.
These technologies are undergoing active development and it is expected
that there will be improvements to the high error rates. For
applications that are more tolerant to error rates, such as structural
variant calling, third generation sequencing has been found to
outperform existing methods.
Current technologies
Sequencing
technologies with a different approach than second-generation platforms
were first described as "third-generation" in 2008-2009.
There are several companies currently at the heart of third generation sequencing technology development, namely, Pacific Biosciences, Oxford Nanopore Technology,
Quantapore (CA-USA), and Stratos (WA-USA). These companies are taking
fundamentally different approaches to sequencing single DNA molecules.
PacBio developed the sequencing platform of single molecule real time sequencing (SMRT), based on the properties of zero-mode waveguides.
Signals are in the form of fluorescent light emission from each
nucleotide incorporated by a DNA polymerase bound to the bottom of the
zL well.
Oxford Nanopore’s technology
involves passing a DNA molecule through a nanoscale pore structure and
then measuring changes in electrical field surrounding the pore; while
Quantapore has a different proprietary nanopore approach. Stratos
Genomics spaces out the DNA bases with polymeric inserts, "Xpandomers", to circumvent the signal to noise challenge of nanopore ssDNA reading.
Also notable is Helicos's single molecule fluorescence approach, but the company entered bankruptcy in the fall of 2015.
Advantages
Longer reads
In
comparison to the current generation of sequencing technologies, third
generation sequencing has the obvious advantage of producing much longer
reads. It is expected that these longer read lengths will alleviate
numerous computational challenges surrounding genome assembly,
transcript reconstruction, and metagenomics among other important areas
of modern biology and medicine.
It is well known that eukaryotic genomes including primates and
humans are complex and have large numbers of long repeated regions.
Short reads from second generation sequencing must resort to
approximative strategies in order to infer sequences over long ranges
for assembly and genetic variant calling. Pair end reads
have been leveraged by second generation sequencing to combat these
limitations. However, exact fragment lengths of pair ends are often
unknown and must also be approximated as well. By making long reads
lengths possible, third generation sequencing technologies have clear
advantages.
Epigenetics
Epigenetic markers
are stable and potentially heritable modifications to the DNA molecule
that are not in its sequence. An example is DNA methylation at CpG
sites, which has been found to influence gene expression. Histone
modifications are another example. The current generation of sequencing
technologies rely on laboratory techniques such as ChIP-sequencing
for the detection of epigenetic markers. These techniques involve
tagging the DNA strand, breaking and filtering fragments that contain
markers, followed by sequencing. Third generation sequencing may enable
direct detection of these markers due to their distinctive signal from
the other four nucleotide bases.
Portability and speed
Other important advantages of third generation sequencing technologies include portability and sequencing speed.
Since minimal sample preprocessing is required in comparison to second
generation sequencing, smaller equipments could be designed. Oxford
Nanopore Technology has recently commercialized the MinION sequencer.
This sequencing machine is roughly the size of a regular USB flash
drive and can be used readily by connecting to a laptop. In addition,
since the sequencing process is not parallelized across regions of the
genome, data could be collected and analyzed in real time. These
advantages of third generation sequencing may be well-suited in hospital
settings where quick and on-site data collection and analysis is
demanded.
Challenges
Third
generation sequencing, as it currently stands, faces important
challenges mainly surrounding accurate identification of nucleotide
bases; error rates are still much higher compared to second generation
sequencing.
This is generally due to instability of the molecular machinery
involved. For example, in PacBio’s single molecular and real time
sequencing technology, the DNA polymerase molecule becomes increasingly
damaged as the sequencing process occurs.
Additionally, since the process happens quickly, the signals given off
by individual bases may be blurred by signals from neighbouring bases.
This poses a new computational challenge for deciphering the signals and
consequently inferring the sequence. Methods such as Hidden Markov Models, for example, have been leveraged for this purpose with some success.
On average, different individuals of the human population share
about 99.9% of their genes. In other words, approximately only one out
of every thousand bases would differ between any two person. The high
error rates involved with third generation sequencing are inevitably
problematic for the purpose of characterizing individual differences
that exist between members of the same species.
Genome assembly
Genome assembly is the reconstruction of whole genome DNA sequences. This is generally done with two fundamentally different approaches.
Reference alignment
When
a reference genome is available, as one is in the case of human, newly
sequenced reads could simply be aligned to the reference genome in order
to characterize its properties. Such reference based assembly is quick
and easy but has the disadvantage of “hiding" novel sequences and large
copy number variants. In addition, reference genomes do not yet exist
for most organisms.
De novo assembly
De novo
assembly is the alternative genome assembly approach to reference
alignment. It refers to the reconstruction of whole genome sequences
entirely from raw sequence reads. This method would be chosen when there
is no reference genome, when the species of the given organism is
unknown as in metagenomics, or when there exist genetic variants of interest that may not be detected by reference genome alignment.
Given the short reads produced by the current generation of
sequencing technologies, de novo assembly is a major computational
problem. It is normally approached by an iterative process of finding
and connecting sequence reads with sensible overlaps. Various
computational and statistical techniques, such as de bruijn graphs
and overlap layout consensus graphs, have been leveraged to solve this
problem. Nonetheless, due to the highly repetitive nature of eukaryotic
genomes, accurate and complete reconstruction of genome sequences in de
novo assembly remains challenging. Pair end reads have been posed as a possible solution, though exact fragment lengths are often unknown and must be approximated.
Hybrid
assembly - the use of reads from 3rd gen sequencing platforms with
shorts reads from 2nd gen platforms - may be used to resolve ambiguities
that exist in genomes previously assembled using second generation
sequencing. Short second generation reads have also been used to correct
errors that exist in the long third generation reads.
Hybrid assembly
Long
read lengths offered by third generation sequencing may alleviate many
of the challenges currently faced by de novo genome assemblies. For
example, if an entire repetitive region can be sequenced unambiguously
in a single read, no computation inference would be required.
Computational methods have been proposed to alleviate the issue of high
error rates. For example, in one study, it was demonstrated that de novo
assembly of a microbial genome using PacBio sequencing alone performed
superior to that of second generation sequencing.
Third generation sequencing may also be used in conjunction with
second generation sequencing. This approach is often referred to as
hybrid sequencing. For example, long reads from third generation
sequencing may be used to resolve ambiguities that exist in genomes
previously assembled using second generation sequencing. On the other
hand, short second generation reads have been used to correct errors in
that exist in the long third generation reads. In general, this hybrid
approach has been shown to improve de novo genome assemblies
significantly.
Epigenetic markers
DNA methylation (DNAm) – the covalent modification of DNA at CpG sites resulting in attached methyl groups – is the best understood component of epigenetic
machinery. DNA modifications and resulting gene expression can vary
across cell types, temporal development, with genetic ancestry, can
change due to environmental stimuli and are heritable. After the
discovery of DNAm, researchers have also found its correlation to
diseases like cancer and autism. In this disease etiology context DNAm is an important avenue of further research.
Advantages
The current most common methods for examining methylation state require an assay that fragments DNA before standard second generation sequencing on the Illumina platform. As a result of short read length, information regarding the longer patterns of methylation are lost.
Third generation sequencing technologies offer the capability for
single molecule real-time sequencing of longer reads, and detection of
DNA modification without the aforementioned assay.
PacBio SMRT technology and Oxford Nanopore can use unaltered DNA to detect methylation.
Oxford Nanopore Technologies’MinION
has been used to detect DNAm. As each DNA strand passes through a pore,
it produces electrical signals which have been found to be sensitive to
epigenetic changes in the nucleotides, and a hidden Markov model (HMM) was used to analyze MinION data to detect 5-methylcytosine (5mC) DNA modification. The model was trained using synthetically methylated E. coli
DNA and the resulting signals measured by the nanopore technology. Then
the trained model was used to detect 5mC in MinION genomic reads from a
human cell line which already had a reference methylome. The classifier
has 82% accuracy in randomly sampled singleton sites, which increases
to 95% when more stringent thresholds are applied.
Other methods address different types of DNA modifications using
the MinION platform. Stoiber et al. examined 4-methylcytosine (4mC) and
6-methyladenine (6mA), along with 5mC, and also created a software to
directly visualize the raw MinION data in human-friendly way. Here they found that in E. coli, which has a known methylome,
event windows of 5 base pairs long can be used to divide and
statistically analyze the raw MinION electrical signals. A
straightforward Mann-Whitney U test can detect modified portions of the E. coli sequence, as well as further split the modifications into 4mC, 6mA or 5mC regions.
It seems likely that in the future, MinION raw data will be used to detect many different epigenetic marks in DNA.
PacBio
sequencing has also been used to detect DNA methylation. In this
platform the pulse width - the width of a fluorescent light pulse -
corresponds to a specific base. In 2010 it was shown that the interpulse
distance in control and methylated samples are different, and there is a
"signature" pulse width for each methylation type. In 2012 using the PacBio platform the binding sites of DNA methyltransferases were characterized. The detection of N6-methylation in C Elegans was shown in 2015. DNA methylation on N6-adenine using the PacBio platform in mouse embryonic stem cells was shown in 2016.
Other forms of DNA modifications – from heavy metals, oxidation,
or UV damage – are also possible avenues of research using Oxford
Nanopore and PacBio third generation sequencing.
Drawbacks
Processing
of the raw data – such as normalization to the median signal – was
needed on MinION raw data, reducing real-time capability of the
technology.
Consistency of the electrical signals is still an issue, making it
difficult to accurately call a nucleotide. MinION has low throughput;
since multiple overlapping reads are hard to obtain, this further leads
to accuracy problems of downstream DNA modification detection. Both the
hidden Markov model and statistical methods used with MinION raw data
require repeated observations of DNA modifications for detection,
meaning that individual modified nucleotides need to be consistently
present in multiple copies of the genome, e.g. in multiple cells or
plasmids in the sample.
For the PacBio platform, too, depending on what methylation you
expect to find, coverage needs can vary. As of March 2017, other
epigenetic factors like histone modifications have not been discoverable
using third-generation technologies. Longer patterns of methylation are
often lost because smaller contigs still need to be assembled.
Transcriptomics
Transcriptomics is the study of the transcriptome, usually by characterizing the relative abundances of messenger RNA molecules the tissue under study. According to the central dogma of molecular biology,
genetic information flows from double stranded DNA molecules to single
stranded mRNA molecules where they can be readily translated into
function protein molecules. By studying the transcriptome, one can gain
valuable insight into the regulation of gene expressions.
While expression levels as the gene level can be more or less
accurately depicted by second generation sequencing, transcript level
information is still an important challenge.
As a consequence, the role of alternative splicing in molecular biology
remains largely elusive. Third generation sequencing technologies hold
promising prospects in resolving this issue by enabling sequencing of
mRNA molecules at their full lengths.
Alternative splicing
Alternative splicing
(AS) is the process by which a single gene may give rise to multiple
distinct mRNA transcripts and consequently different protein
translations.
Some evidence suggests that AS is a ubiquitous phenomenon and may play a
key role in determining the phenotypes of organisms, especially in
complex eukaryotes; all eukaryotes contain genes consisting of introns
that may undergo AS. In particular, it has been estimated that AS occurs
in 95% of all human multi-exon genes.
AS has undeniable potential to influence myriad biological processes.
Advancing knowledge in this area has critical implications for the study
of biology in general.
Transcript reconstruction
The
current generation of sequencing technologies produce only short reads,
putting tremendous limitation on the ability to detect distinct
transcripts; short reads must be reverse engineered into original
transcripts that could have given rise to the resulting read
observations.
This task is further complicated by the highly variable expression
levels across transcripts, and consequently variable read coverages
across the sequence of the gene. In addition, exons may be shared among individual transcripts, rendering unambiguous inferences essentially impossible.
Existing computational methods make inferences based on the
accumulation of short reads at various sequence locations often by
making simplifying assumptions. Cufflinks takes a parsimonious approach, seeking to explain all the reads with the fewest possible number of transcripts. On the other hand, StringTie attempts to simultaneously estimate transcript abundances while assembling the reads. These methods, while reasonable, may not always identify real transcripts.
A study published in 2008 surveyed 25 different existing transcript reconstruction protocols.
Its evidence suggested that existing methods are generally weak in
assembling transcripts, though the ability to detect individual exons
are relatively intact.
According to the estimates, average sensitivity to detect exons across
the 25 protocols is 80% for Caenorhabditis elegans genes.
In comparison, transcript identification sensitivity decreases to 65%.
For human, the study reported an exon detection sensitivity averaging to
69% and transcript detection sensitivity had an average of mere 33%. In other words, for human, existing methods are able to identify less than half of all existing transcript.
Third generation sequencing technologies have demonstrated
promising prospects in solving the problem of transcript detection as
well as mRNA abundance estimation at the level of transcripts. While
error rates remain high, third generation sequencing technologies have
the capability to produce much longer read lengths. Pacific Bioscience has introduced the iso-seq platform, proposing to sequence mRNA molecules at their full lengths.
It is anticipated that Oxford Nanopore will put forth similar
technologies. The trouble with higher error rates may be alleviated by
supplementary high quality short reads. This approach has been
previously tested and reported to reduce the error rate by more than 3
folds.
Metagenomics
Metagenomics is the analysis of genetic material recovered directly from environmental samples.
Advantages
The main advantage for third-generation sequencing technologies in metagenomics
is their speed of sequencing in comparison to second generation
techniques. Speed of sequencing is important for example in the clinical
setting (i.e. pathogen identification), to allow for efficient diagnosis and timely clinical actions.
Oxford Nanopore's MinION was used in 2015 for real-time
metagenomic detection of pathogens in complex, high-background clinical
samples. The first Ebola virus (EBV) read was sequenced 44 seconds after data acquisition.
There was uniform mapping of reads to genome; at least one read mapped
to >88% of the genome. The relatively long reads allowed for
sequencing of a near-complete viral genome to high accuracy (97–99%
identity) directly from a primary clinical sample.
A common phylogenetic marker for microbial community diversity studies is the 16S ribosomal RNA gene. Both MinION and PacBio's SMRT platform have been used to sequence this gene. In this context the PacBio error rate was comparable to that of shorter reads from 454 and Illumina's MiSeq sequencing platforms.
Drawbacks
MinION's high error rate (~10-40%) prevented identification of antimicrobial resistance markers, for which single nucleotide resolution is necessary. For the same reason eukaryotic pathogens were not identified.
Ease of carryover contamination when re-using same the flow cell
(standard wash protocols don’t work) is also a concern. Unique barcodes
may allow for more multiplexing. Furthermore, performing accurate
species identification for bacteria, fungi and parasites is very difficult, as they share a larger portion of the genome, and some only differ by <5 nbsp="" p="">
The per base sequencing cost is still significantly more than
that of MiSeq. However, the prospect of supplementing reference
databases with full-length sequences from organisms below the limit of
detection from the Sanger approach; this could possibly greatly help the identification of organisms in metagenomics.
Before third generation sequencing can be used reliably in the
clinical context, there is a need for standardization of lab protocols.
These protocols are not yet as optimized as PCR methods.
.jpg)